
突破区块链不可能三角(三)——POS与POW-DAG



在上篇中,我们主要讨论了POW为什么不可扩展,以及如何实现可扩展的POW。我们再来把逻辑捋一捋——
1,POW是个公平的基于算力的随机产生方法,然而,它的有效性是建立在时间的基础上的,也就是说,在计算成功挖出区块的概率时,不仅仅要考虑你的算力在总算力的比例m,还要考虑你有效挖矿的时间t。换句话说,虽然我们总说如果恶意节点不拥有超过50%的算力时没法攻击比特币,然而,这里并没有考虑到时间t。也就是说,这里的50%是建立在诚实节点都在 有效挖矿 的基础上的。
2,那么,什么是有效挖矿呢?在比特币的POW里,只有在最长链上挖矿才叫有效挖矿。如果而每当一个合法区块挖出的时候,实际上拥有合法区块的链就成了最长链。而这个时候,哪怕你由于没来的及收到新区块而在原来的区块上多挖了一秒钟,你其实都在 无效挖矿 。但是对于比特币POW而言,从一开始就没有想过要避免无效挖矿的情况。它做的事情就是让无效挖矿损失的算力相比于所需要的总算力可以忽略,于是我们仍旧有接近50%的安全性。
3,那么,在什么时候这些浪费的算力不可忽略了呢?有两种情况,a)当浪费的算力增加的时候;b)当目标算力降低的时候。当增大区块的时候,由于区块所需同步的时间变长,于是从一个矿工发布有效区块开始,其他还没有来得及完成同步的矿工无效挖矿的时间也变长,于是,更多的算力被浪费了。而减小区块间隔,也就是相当于降低目标难度。两者都会使浪费的算力在总算力中所占的比重增加,导致POW算法的安全性下降。
3.5,这里我们需要注意的是——并不是只有当分叉的时候才代表了算力被浪费,也就是说说,即便不考虑分叉,随着输出的增加,安全性也会下降。但实际上对于安全性更严重的伤害是分叉,因为分叉会导致一定比例的算力会被浪费在孤块上。无论是何者,我们都看到了同一个结论——算力被浪费的比例随着区块大小B(大约)增加而增加,随着区块间隔s(大约)增加而减少,而B/s却恰恰是比特币的输出。于是,比特币POW的缺陷是——
比特币的安全性和输出成反比,随着输出不断增大,比特币POW的安全性无限趋近于0。
4,于是,想要获得更高的输出,我们需要改进比特币的POW算法,使得矿工能够更加有效的挖矿,即,去掉POW对于有效挖矿的限制。那么,如何能够更加有效地挖矿呢?在POW中,只有在最长链上挖矿才是有效挖矿,即, 只有先同步最新的区块,即,同步所有交易,才能进行有效挖矿,而等到挖矿出了新区快,才能开始对于新区块的同步,也就是说这两个的关系是互相依赖的。

5,因此,想要改进比特币POW,我们要去掉POW的安全性对于同步交易的依赖,也就是说,必须把交易的传输和POW脱钩。再换个说法,就是绝对不应该对矿工的挖矿有同步整个账本的限制。
以上,就是扩展比特币POW的推理过程。应该说,里面的每一环都是必要的——也就是说,任何用POW做共识的算法,都需要考虑这些问题,也都会受到一样的限制。
然后,我们讨论了两种将传输和POW并行的思路——
1,领袖选择:用挖矿决定出块者而不是内容,即交易。这样的话,有效挖矿就不对同步所有交易做要求了,而只是“所有节点能够同步当前正确的出块者”,而这点是容易做到的。然而,它的缺陷是,对于恶意出块者的作恶行为没有约束力。因为如果我们仍旧依照“发现恶意交易就不接受并且分叉”的逻辑来执行的话,就相当于又使POW依赖于交易的同步了。因此,我们只有两个选择——a)通过一些方法来惩罚恶意出块者;b)保证出块者不作恶。前者就是Bitcoin-NG所采用的方法——如果前面有出块者作恶,那么后面的出块者可以通过某些特殊的交易拿走之前出块者的所有奖励。而后者则不能只选取一个出块者,而是需要选取很多出块者,即某个委员会。例如,我们选取前20个区块的区块发布者(即前二十个成功算出目标哈希值的矿工)。然后委员会内部通过BFT算法决定一个区块。这里需要考虑的问题是,首先委员会不能有超过1/3的恶意节点(因为要做BFT),而这点只能通过概率保证,例如,当整个网络中恶意算力不超过1/4的时候,我们可以通过大数定理保证选出20个矿工他们其中恶意的矿工数量超过1/3的可能性非常小,然而,我们却没法说如果我们只选4个矿工,那么一定最多有一个矿工是恶意的。因此,最终这个委员会的大小决定了系统的容错性,委员会越大,容错性越高,但由于要做BFT,因此延迟会更大。
2,将非最长链上的算力也纳入有效算力。这点,我们介绍了GHOST。在GHOST之中,最长链共识被改成了最重子树共识,而矿工不限定只指向前一个区块,而可以指向其他看到的深度为1的孤块,即下图这种结构:
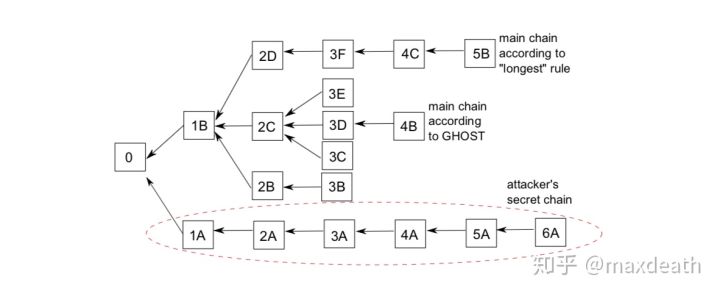
从有效挖矿的角度讲,GHOST的意义是:即便矿工没有及时完成对于最新块的同步,并且导致你在别人之后才挖出了区块,你的算力也不会浪费,同时,也不容易导致后续分叉,造成算力的浪费。
然而,GHOST仍旧不是最优的做法,因为如果同步所需要的时间超过了一个区块间隔,你挖出的区块仍旧可能无法被纳入最重链,于是算力仍旧被浪费了。因此,如果从之前安全性和输出的角度考虑画一条曲线的话,GHOST在输出不高的情况下安全性和比特币POW一样,然后,随着输出提高,然后,在很小的一个区间内,比特币的安全性下降但是GHOST的安全性不变。也就是说,GHOST能够将输出提升到这个区间。再之后,随着输出继续增加,GHOST和比特币POW的曲线是没有什么区别的,最终都会变成0。
然而,我们可以把GHOST的思路推广开来——例如,我们可以允许节点接受深度为2的孤块,继而是深度为3的孤块……最终,让所有挖出的区块都不会浪费,都能贡献给系统的安全性。从结果上来看,我们将会无限扩大GHOST那个安全性不随输出变化的区间,最终得到一个安全性不依赖于输出的算法。而从实现方法上看,其实这样的系统,就是一个DAG。
之所以我又花了这么大的篇幅又唠叨了一边比特币可扩展性的问题,是因为POS和POW-DAG的可扩展性以及他们采用的方法在很大程度上就是前文中可扩展比特币POW算法的自然演化版,我们先从POS说起。
权益证明POS
在前文中我们也看到了,可扩展POW的算法基本上都是3-4年前甚至更早的了。原因很简单——在学术界,大多数人都转向了POS。在这里,我们先略过许可与非许可之争以及POW和POS之争,所以我先不去详述POS和POW的优劣(这个我可能最近会单开一篇谈一谈)。但是事实就是,在学术界的非许可链的共识算法这个问题上,大部分更新的算法都选择了POS。POS,权益证明,顾名思义,就是相对于POW的“算力越高,挖出快的概率越大”的方法,改成“钱越多,挖出块的概率越大”。然而,相对于一说POW我们就会想到比特币POW不同,POS并不是仅仅指某一种算法,而是这一类用权益作为权重进行出块者选取的方法。
在这里,我就跳过早期peercoin和NXT的POS,也跳过DPOS以及以太坊Casper,我们只从输出的角度简单地叙述几个比较典型并且有比较严谨的学术论文的,基于随机数的POS:Snow White,Ouroboros,Algorand和Dfinity。
无论是从可扩展性角度还是实现角度,这几个算法都可以说是可扩展POW的领袖选择思路在POS中的对应。其中,Snow White和Ouroboros相当于Bitcoin-NG的POS对应,而Algorand和Dfinity则是Hybrid Consensus和Byzcoin的对应。
但是,这里有一个必须要先解释一下的问题——这几个算法的随机数是怎么产生的。

恩……果然这一篇解释不完,所以在这篇里,我们姑且认为有这样一个神(随机预言机,Random Oracle)可以每隔一个时间t就提出一个真·随机数,然后,我们可以通过这个随机数和当前账本上每个人拥有的钱数,进行一个带权重的抽签来决定每一轮的出块者……
细心地朋友已经察觉出问题了——
我们在比特币中费那么大力气挖矿不就是为了实现这个么?你现在用一个“神”就把我们打发了?
然而,事实就是这么回事。在我看来,之所以后来学术界纷纷转向POS,实际上就是看到了这个问题:“这个问题不就是我们研究了很久的随机数的东西么,我们完全可以通过密码学解决,为啥要用又费电又费时的POW?”
于是,实际上上面的每个POS算法,都在某种假设下,从某种程度上实现了这个“神”的功能,因此,我在这里就直接用“神”替代了,而先略过实现的细节。
有了这个“神”之后,我们实际上就不再有之前的烦恼了,也就是,需要并行共识和传输的烦恼,因为我们可以把几乎所有的带宽*时间用于传输和验证而不担心影响系统的安全性。换言之,我们可以采用最简单的级联结构而把区块设置得尽可能大——例如,10分钟内能够同步多大的区块,就设多大,而不用担心共识的时间不够导致系统安全性下降的问题。

于是,既然我们能够把所有的带宽*时间都用于消息传输了,这些POS的算法和可扩展POW应该是接近的。
这其中,Snow White和Ouroboros类似Bitcoin-NG,只有一个领袖负责出块。而Algorand和Dfinity则类似Byzcoin和Hybrid Consensus,采用一个负责出块的委员会。两者相较,以输出而论,两者各有千秋。前者在一个更诚实和节点更活跃的网络中表现更好,因为在理想状态,这就是一个大家轮流出块的系统,然而,它在节点不活跃或者恶意的情况下容易出现空时段或者分叉的情况导致带宽的浪费,以及相对而言更高的确认时间。后者由于采用委员会,所以这种情况只有在整个委员会不活跃或者恶意的情况下才会出现,因此出现概率会随着委员会人数的提高而降低。然而,委员会之间的通信,通常采用传统BFT或者可扩展的BFT,所需的时间和消息复杂度会带来更高的延迟,乃至相比于将消息广播到全网而言不可忽略(如果人数太多的话)的通信复杂度。这两者的适用场景会有区别,个人认为,对公链而言,由于所处网络环境的复杂性,后者的输出和延迟更加稳定。
POW+DAG
正如前文所说,DAG是GHOST想法的延伸——但是,GHOST和DAG之前还有一个中间步骤:在GHOST中,叔块是只计算算力但不考虑里面包含的数据的。于是,如果我们将GHOST的想法继续扩展,我们最终得到的结果是,无论我们如何增加区块大小(或者缩小区块间隔),算力都不会被浪费,于是,我们可以获得比比特币POW更高的输出。然而,这个结果只是保证了算力不被浪费,但是用于传播非主链上的区块的带宽还是被浪费了。举个例子,如果我们将区块大小增加到100MB,于是网络中平均在每个时间段都存在3个合法区块。在比特币POW中,这种情况会导致算力分散和安全性下降。但如果采用了GHOST的模式,这种情况不会发生,但是我们最终需要每10分钟传输300MB的区块,而最终被保留的只有100MB的交易,剩下的部分都被浪费了,这显然不是我们想要的。
于是,如果我们选择也保留这两个区块,我们才得到了理想的DAG——
每个矿工只需要1,打包交易;2,尽量同步新区块并且连上;3,挖矿,在挖到之后就把区块发布出去。然后,最终的结果是,无论是你打包的交易,还是你挖矿的算力,最终都会成为共识的一部分。(这里有个坑,我们一会再说)
我们可以从两个角度来理解DAG:
第一个角度,从结构上来说,它不再是一条链,而是一个图,但更确切地说,它是一条带子,例如下图:
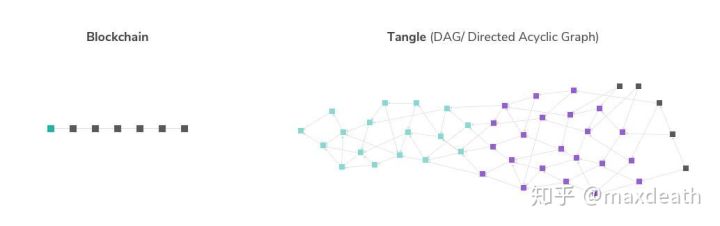
这张图可以帮助我们对于区块链中DAG的样子有一个非常直观的认识——因为DAG(有向无环图)只是一个定义,但是它的形态却并不止一种。而从这张图上,我们能看出来区块链中DAG大概长啥样:
1,首先,它不是一个链,但是,也不是一个无线变大的如同树状的图,它更像一条带子,而带子长度是时间,而宽度我们可以认为是同一段时间同时产生的区块。
2,于是,宽度实际上代表了这个DAG的输出,当宽度是1个区块的时候,我们实际上获得了区块链。而假设宽度是10个区块,我们相当于把区块链的输出提高了10倍。
3,与链式结构不同的地方在于,当矿工发布区块的时候,它不需要同步网络中所有的区块,而只需要同步一部分区块就可以了。在这幅图中,是所有在它之前并且直接或间接相连的区块。
4,于是,在最终,所有的矿工仍旧会对这条带子上的所有交易达成共识,也就是图中浅蓝的部分。这就是我在第一部分中所说的,DAG并不是无限扩展算法,因为它仍旧要求所有矿工对所有节点达成共识。
5,最终,一个区块被确认的前提是——它大概率不会被分叉,除非有人拥有超过50%算力。
那么,这个带子的宽度由什么决定呢?
答案是网络本身的特性(例如网速,拓扑结构)和区块链本身的参数(例如区块大小,间隔等),而后者,在理想状态下应该被设计成正好能够完全利用整个网络的带宽——这是什么概念呢?我们来换个角度:
假设你是一个矿工,理想的状态是,你一边坐着火车(挖着矿),一边吃着火锅(同步着区块),一边唱着歌(验证着交易),然后矿挖好了发布区块的时候,你正好也把之前你发现的网络中所有的区块同步并且验证完了,而在挖矿期间,你又发现了新的区块正好可以在下一轮挖矿的时候进行同步……

如果所有矿工都处于理想状态,那么,这个网络中的带宽就被全部利用了。
然而,如果有矿工常常出现:火车还在开火锅吃完了,那么就说明带宽并没有被很好的利用,于是我们可以增大区块或者缩小区块间隔来提高输出。这种提高输出放在图里的体现,就是更多(更大)的区块会在同一个时间段被创造出来,于是带子变宽了。
另一个情况是,如果出现大量矿工无法同步所有区块的情况呢?显然,这个时候说明我们需要把输出降低一些。但是,如果我们不降低输出,会发生什么情况呢?
第一,既然网络的容量是一定的,所以最终得到确认的交易数量肯定不会增加。但问题是,因为新增的区块太多,那么对于矿工而言,就很难对于新增的区块达成一致的共识,最终导致的结果,就是——这条带子会变得越来越宽,而不是越来越长。因此,大部分的DAG需要对于这样的情况加以限制,所以通常DAG会给新挖出的区块以更大的权重,来鼓励这条带子往长而不是往宽的方向发展。同时,这也可以限制恶意节点故意从老区块上建立分叉的行为。
第二,这样的话,那些不能及时同步所有区块的矿工,会由于无法将他们的区块加在最新的区块上,导致他们的区块不能带来足够高的权重(因为太旧了)而被其他节点放弃。最终,这些区块和算力会被浪费。
第三,由于网络中节点的网络状况和算力是不均等的,所以必然有的节点会出现火锅没吃完车停了的情况,有的节点会出现车开着火锅吃完了的情况。因此,最终我们会调节区块链的参数,使得整个带子处于一个两者均衡的状态,以期达到最大的输出和浪费最少的算力。
听起来很好,不是吗?
DAG似乎只是一个简单的对于链式结构的扩展而已,我们减弱了链式结构中输出和安全性的相关性,最终能够通过调节参数,近似地利用所有的网络容量,达到接近最优的输出。
看上去,我们在这期间没有牺牲掉任何东西,不是么?
可惜,答案是否定的。
DAG中的定序问题
其实,区块链以及一切BFT算法,除了要对内容(区块)达成共识,也必须对于这些内容的先后顺序达成共识。换句话说,顺序也是共识中不可缺少的一部分。在PBFT中,两轮的通信中第一轮就是定序。
对于比特币POW而言,由于采用链式结构,所以定序和共识是同时进行的——当一个矿工引用了前一个区块的时候,自然而然就表明了这两个区块之间的顺序。
但在DAG中,虽然所有节点最终对于所有区块会达成共识,同时由于图的有向性,对于一条支链上的所有区块是有共识的,但是,如果两个区块互相之间并不能直接相连,那么两个区块之间的顺序是没有共识的,例如:
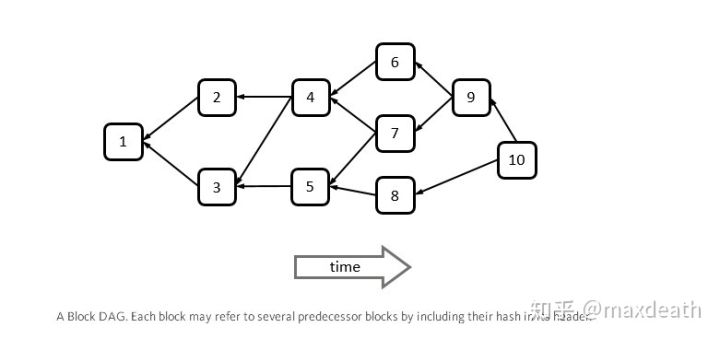
可能有人会问:顺序有这么重要吗?
答案是:在有些时候,可能没这么重要,这也是为什么IOTA号称“用于IOT”,因为他们自己很清楚IOTA的算法tangle是无法定序的,于是,就无法用于数字货币。
因为,数字货币需要定序才能决定两笔冲突的交易哪笔合法哪笔非法——
之前已经提到过,从GHOST到DAG的重要一步是,我们需要把同时产生的多个区块的交易全部纳入共识。这其中不可避免的两个问题是:
1,重复的交易会降低输出,这个我们一会再说。
2,冲突的交易,例如一个交易X说A把钱付给了B,一个交易X'说A把钱付给了C,这两个冲突的交易都纳入共识的话,我们必然需要一个一致性的算法来判定哪个是真的,而这就必然涉及到顺序的问题,可是如果所有的节点无法对两者的顺序达成共识,也就无法对于这两笔交易的合法性达成共识。而无法对于合法性达成共识的结果,就代表这两笔交易永远无法得到确认,换句话说就是达不到活性。
这是一个非常麻烦的问题,目前为止,有两个思路:
思路一:通过后面区块的拓扑结构来定序
这是GHOST的小组一直在尝试的方法,从SPECTRE到PHANTOM他们都采用了区块虚拟投票的方法,即,由后面的区块来决定谁先谁后。
他们设计了一种投票机制,来使投票的结果可以快速收敛到某一边——假设由于出现时间先后或者由于随机的原因,后面连着含有交易X的区块略多于连着含有X'的区块,那么,这个算法会保证结果会随着时间增长越来越压倒性地偏向X,最终迅速地收敛至X。
但是这个设计的问题在于,没法保证投票的结果一定会偏向向某一边——尤其是恶意节点可以通过很少的算力就去维持两边的平衡。
SPECTRE对于这个问题的解决方案是:不解决。
SPECTRE做出了这样一个假设:这是一个虚拟货币,如果X和X'同时出现,那么A一定在短时间内签署了两笔冲突的交易,那么他是恶意节点。于是,我们没必要保证这样的交易的活性。也就是说,如果恶意节点想要一直通过平衡两条差不多重的分支来让别人无法确认两笔交易谁合法的话,那就随它去,反正这是恶意节点的交易。
而那些诚实节点发出的交易,我们可以保证活性,并且确认任何两笔交易之间的先后顺序。
但这个假设就造成了SPECTRE的局限性使他无法作为图灵完备的区块链系统的算法,因为在那里面,我们需要全序性。因为智能合约也许需要判定两个不同的人发布的消息的先后。
于是Phantom和BlockDAG都致力于基于投票来解决这个问题,他们主要的思路是希望能够证明诚实的网络组成的图一定会有某些特性,并且,可以用之前的虚拟投票方法来定序。但一些恶意节点创造出来想要破坏全序性的分支一定不具备这些特性。于是,我们只需要通过某种判别方法筛出那些恶意节点创造出的分支。
然而,目前他们给出的判别方法还是有问题。而且,从某种角度看,它实际上就是复杂化的第二种思路:
思路二:确定一条主链
实际上,如果我们能够确定一条主链,我们就可以很容易地根据主链和一套确定性的规则来对所有区块定序了。
然而,确定主链并不容易——因为DAG是长这样的:
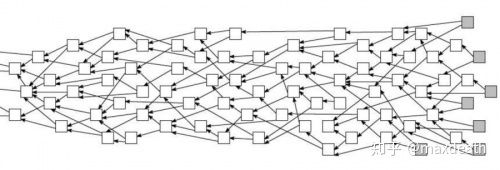
如果网络均匀分布的话,那么我们大概率得到的是n条几乎差不多长而且匀速增长的链,想要从中确认一条主链,实际上几乎和定序一样难。除非我们能够在算法上进行一些改动,让算法能够更容易收敛出一条主链。但是,在这样的DAG结构中,需要收敛出一条主链就代表着矿工需要优先同步主链,而不能同步的节点就面临算力被浪费的风险。从这个角度讲,在这种DAG结构下,想要追求定序也可以,但是代价是输出的降低。
在这方面,Prism在这种结构上做出了改进——它从结构上把DAG拆解开,然后用传统的链式结构生成主链,然后用类似DAG的结构进行出块。从一种角度讲,它解决了DAG的定序问题,但是从另一种角度讲,它又很像Bitcoin-NG,唯一的区别就是micro block不再由领袖生成,而是由各个节点生成再用DAG的形式连在主链上……
而这就为POW-DAG和可扩展POW,建立了一座桥梁。
DAG的重复交易问题
DAG中绕不开的另一个问题,是重复交易。尤其是在比特币这种所有矿工共享交易池的系统里,如果每个节点都自行往外捞交易打包的话,那么必然会出现“矿工生成的区块中有大量重复交易”的情况,这就完全失去了我们采用DAG把一条链变成一条带子的意义——诚然,每个时间间隔达成共识的区块从一块变成三块,从100MB变成300MB,但是如果这300MB之中每个交易都被打包了三遍,那区块链的实际输出等于没变,反而需要储存和传输的数据多了三倍。于是有人会问:重复率会有这么高么?
但是实际上,如果沿用比特币现在的交易池结构的话,重复率几乎一定是这么高的,因为所有矿工都用同样的规则从同一个池子里捞交易——而这样的话,其实输出不仅几乎没有提升,反而还要造成储存空间的浪费(因为重复交易也需要被传输和储存才能验证区块是否合法)。
所以,采用DAG的时候矿工必须同时采用一个不一样的交易选取机制——要么,取消交易池,把每个节点就近或者随机分给一个矿工负责打包交易;要么,矿工需要采用随机的方式从交易池里捞交易。
但两者其实都只能治标,不能治本——
前者会造成中心化。换句话说,如果接受你交易的矿工下线或者恶意,又甚至说它单纯地能力不行,都会导致你的交易无法被确认,那么结果就是你还是需要把你的交易广播给更多的矿工,于是再次造成重复交易。
后者则需要做一个“矿工会诚实地随机从池子里选取交易的假设”,但这个和“理性矿工应该优先选择交易费高的交易”是相悖的。如果严格约束前者,会同时损害矿工和交易者的利益,因为矿工有可能会无法获得最优的交易费,而交易者也无法通过提高交易费来保证自己的交易更快被矿工打包。因此,这招更像是在“交易市场”中采取“计划经济”的手段来强制分配资源。
但无论如何,重复交易对于DAG输出的影响都是巨大的——即便作为交易者,你只把你的交易多发给一个矿工作为备用方案,都会导致50%的交易重复,即输出下降50%,或者说,千辛万苦提高了的网络使用率,就这样被抹去了50%。
(大家有没有想起一个人?)

IOTA作为最早的DAG之一,自然想过这个问题,所以它取消了区块和矿工的设定,让交易者自行进行POW和上传交易。然而,这种做法不仅带来了更严重的安全隐患,同时引入了另一个导致重复交易的设定——tangle算法里假设诚实节点会努力提高自己的交易被接受的速度,甚至可以继续在自己的交易后面连上空交易来增加自己交易被别人引用的几率,这其实是变相地在鼓励交易者为交易浪费更多的带宽。
但是,IOTA的有一点思路是没错的——如果在某个场景下,矿工本身不是从池子里捞交易而是自己生成交易并打包上链的话,那么这就不存在重复交易的问题。
可扩展POW和POW-DAG之间的比较
实际上,尽管看上去完全不同,在之前的介绍中我们也把这两个说成是两种不同的路线,但两者的输出其实是可以从某种角度比较的——比如,以Bitcoin-NG,Hybrid Consensus和Prism为例。
三者都有类似主链的东西,并且也都支持消息的全序,那么以主链的一个区块为一轮来算的话。
Bitcoin-NG:领袖负责出块并把消息广播到全网,不能完全地利用带宽进行消息广播(由于只有领袖广播),同时,输出可能会受到恶意领袖的影响。
Hybrid Consensus:委员会负责出块并把消息广播到全网,可以更好利用带宽(随机选取的委员会成员可以更快将消息广播给全网),但必须要考虑委员会之间采用BFT算法的通信冗余。
Prism:所有节点自行出块并用DAG最终达成共识,可以最大程度地利用带宽,但必须考虑重复消息的问题。
我们之前对比了前两者在不同网络状况中的优劣势,但是和DAG对比起来会更加复杂,因为重复消息对于输出的影响极大,却又极大取决于前文所述矿工采取的策略。
下一篇,我们会介绍一些可扩展BFT的思路。


