
SevenX Ventures:一文读懂ZKML - 零知识证明和区块链如何在人工智能和机器学习领域发挥作用?




本文为 SevenX 研究团队原创,仅供交流学习,不构成任何投资参考。如需引用,请注明来源。
原版英文报告于 2023 年 5 月发表于 SevenX 的 Mirror 平台。更多中文投研内容,请关注公众号【SevenXVentures】。
感谢 Brian Retford, SunYi, Jason Morton, Shumo , Feng Boyuan, Daniel, Aaron Greenblatt, Nick Matthew, Baz, Marcin, 和 Brent 对本文提供的宝贵见解、反馈和审阅。
作者:Grace&Hill
对于我们这些加密爱好者来说,人工智能已经火了好一阵子。有趣的是,没人愿意看到人工智能失控的情况。区块链发明的初衷是防止美元失控,所以我们可能会尝试一下防止人工智能的失控。此外,我们现在有了一种叫做零知识证明的新技术,用于确保事情不会出错。然而,要驾驭人工智能这个野兽,我们必须了解它的工作原理。
机器学习的简单介绍
人工智能已经经历了几个名字的变化,从“专家系统”到“神经网络”,然后是“图形模型”,最后演变为“机器学习”。所有这些都是“人工智能”的子集,人们给它起了不同的名字,我们对人工智能的了解也在不断加深。让我们稍微深入了解一下机器学习,揭开机器学习的神秘面纱。

注:如今,大多数机器学习模型都是神经网络,因为它们在许多任务中具有优异的性能。我们主要将机器学习称为神经网络机器学习。
机器学习是如何工作的?
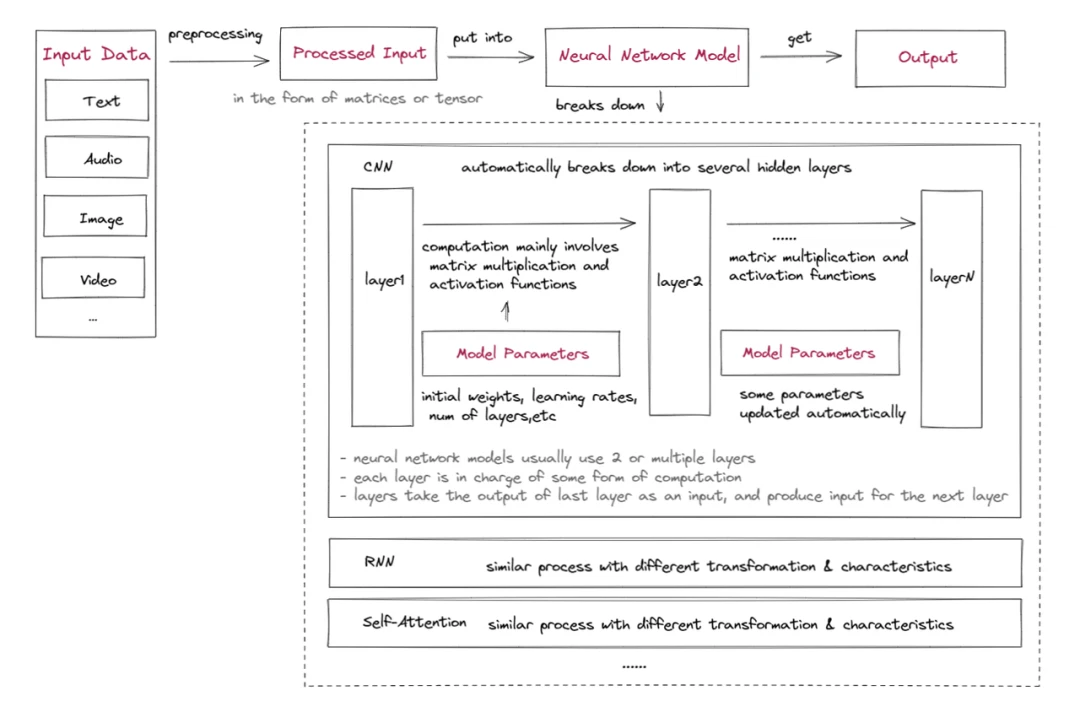
首先,让我们快速了解一下机器学习的内部运作:
-
输入数据预处理:输入数据需要处理成可以作为模型输入的格式。这通常涉及预处理和特征工程,以提取有用的信息并将数据转换成合适的形式,如输入矩阵或张量(高维矩阵)。这是专家系统方法。随着深度学习的出现,处理层自动处理预处理。
-
设置初始模型参数:初始模型参数包括多个层、激活函数、初始权重、偏置、学习率等。有些参数可以在训练过程中通过优化算法进行调整以提高模型的准确性。
-
训练数据:
-
输入数据输入到神经网络中,通常从一个或多个特征提取和关系建模层开始,如卷积层(CNN),循环层(RNN)或自注意力层。这些层学会从输入数据中提取相关特征并建模这些特征之间的关系。
-
这些层的输出然后传递给一个或多个额外的层,这些层对输入数据执行不同的计算和转换。这些层通常主要涉及可学习权重矩阵的矩阵乘法和非线性激活函数的应用,但也可能包括其他操作,如卷积神经网络中的卷积和池化,或者循环神经网络中的迭代。这些层的输出作为模型中下一层的输入,或者作为最终的预测输出。
-
获取模型的输出:神经网络计算的输出通常是一个向量或矩阵,表示图像分类的概率、情感分析分数或其他结果,具体取决于网络的应用。通常还有一个错误评估和参数更新模块,根据模型的目的自动更新参数。
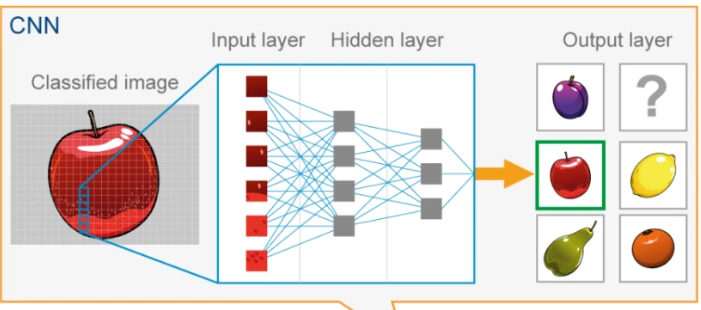
神经网络计算的输出通常是一个向量或矩阵,表示图像分类的概率、情感分析分数或其他结果,具体取决于网络的应用。通常还有一个错误评估和参数更新模块,根据模型的目的自动更新参数。如果上述解释看起来太晦涩,可以参考以下使用 CNN 模型识别苹果图片的例子。
-
将图像以像素值矩阵的形式加载到模型中。该矩阵可以表示为具有尺寸(高度、宽度、通道)的3D张量。
-
设置 CNN 模型的初始参数。
-
输入图像通过 CNN 中的多个隐藏层,每个层应用卷积滤波器从图像中提取越来越复杂的特征。每层的输出通过非线性激活函数,然后进行池化以减小特征图的维数。最后一层通常是一个全连接层,根据提取的特征生成输出预测。
-
CNN 的最终输出是概率最高的类别。这是输入图像的预测标签。
机器学习的信任框架
我们可以将上述内容总结为一个机器学习信任框架,包括四个机器学习的基本层,整个机器学习过程需要这些层是可信的才能可靠:
-
输入:原始数据需要进行预处理,有时还需要保密。
完整性:输入数据未被篡改,未被恶意输入污染,并且正确地进行了预处理。
隐私:如有需要,输入数据不会泄露。
-
输出:需要准确生成和传输
完整性:输出正确生成。
隐私:如有需要,输出不会泄露。
-
模型类型/算法:模型应正确计算
完整性:模型执行正确。
隐私:如有需要,模型本身或计算不会泄露。
不同的神经网络模型具有不同的算法和层,适用于不同的用例和输入。
卷积神经网络(CNN)通常用于涉及网格状数据的任务,如图像,其中局部模式和特征可以通过对小输入区域应用卷积操作来捕获。
另一方面,循环神经网络(RNN)非常适用于顺序数据,如时间序列或自然语言,其中隐藏状态可以捕获来自先前时间步的信息并建模时间依赖关系。
自注意力层对于捕获输入序列中元素之间的关系非常有用,使其对于诸如机器翻译或摘要之类的任务非常有效,这些任务中长程依赖关系至关重要。
还存在其他类型的模型,包括多层感知机(MLP)等。
-
模型参数:在某些情况下,参数应该透明或民主生成,但在所有情况下都不易被篡改。完整性:参数以正确的方式生成、维护和管理。隐私:模型所有者通常会对机器学习模型参数保密,以保护开发该模型的组织的知识产权和竞争优势。这种现象只在变压器模型变得疯狂昂贵的训练前非常普遍,但对行业来说仍然是一个主要问题。
机器学习的信任问题
随着机器学习(ML)应用的爆炸式增长(复合年增长率超过 20% )以及它们在日常生活中的日益融入,例如最近备受欢迎的 ChatGPT,机器学习的信任问题变得越来越关键,不容忽视。因此,发现并解决这些信任问题至关重要,以确保负责任地使用 AI 并防止其潜在滥用。然而,究竟是哪些问题呢?让我们深入了解。

透明度或可证明性不足
信任问题长期困扰着机器学习,主要原因有两个:
-
隐私性质:如上所述,模型参数通常是私密的,而在某些情况下,模型输入也需要保密,这自然会在模型所有者和模型用户之间带来一些信任问题。
-
算法黑盒:机器学习模型有时被称为“黑盒”,因为它们在计算过程中涉及许多难以理解或解释的自动化步骤。这些步骤涉及复杂的算法和大量的数据,带来不确定性和有时随机的输出,使得算法容易受到偏见甚至歧视的指责。
在更深入之前,本文的一个更大的假设是模型已经“准备好使用”,意味着它经过良好的训练并符合目的。模型可能不适用于所有情况,而且模型以惊人的速度改进,机器学习模型的正常使用寿命在2到18个月之间,具体取决于应用场景。
机器学习信任问题的详细分解
模型训练过程中存在一些信任问题,Gensyn目前正在努力生成有效证明以促进这一过程。然而,本文主要关注模型推理过程。现在让我们使用机器学习的四个构建模块来发现潜在的信任问题:
-
输入:
数据来源是防篡改的
私有输入数据不被模型操作者窃取(隐私问题)
-
模型:
模型本身如宣传的那样准确
计算过程正确完成
-
参数:
模型参数没有被改变或与宣传的一致
在过程中,对模型所有者具有价值的模型参数没有泄露(隐私问题)
-
输出:
输出结果可证明是正确的(可能随着上述所有元素的改进而改进)
如何将 ZK 应用到机器学习信任框架中
上述一些信任问题可以通过上链来解决;将输入和机器学习参数上传到链上,并在链上计算模型,可以确保输入、参数和模型计算的正确性。但这种方法可能会牺牲可扩展性和隐私性。 Giza 正在 Starknet 上进行这项工作,但由于成本问题,它仅支持像回归这样的简单机器学习模型,不支持神经网络。ZK 技术可以更有效地解决上述信任问题。目前,ZKML 的 ZK 通常指 zkSNARK。 首先,让我们快速回顾一下 zkSNARK 的一些基本概念: 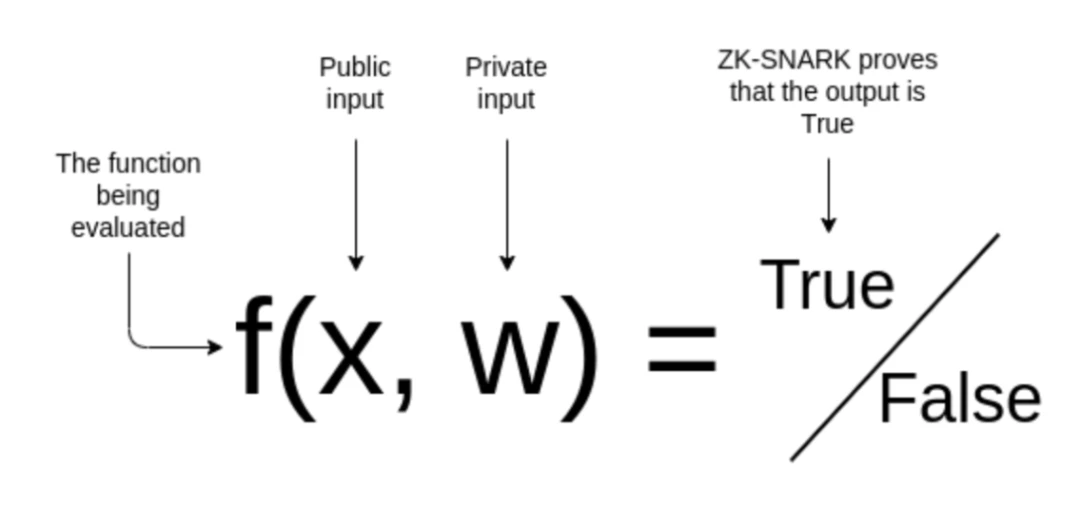
-
制定需要证明的陈述:f(x, w)=true
“我使用具有私有参数 w 的机器学习模型 f 正确地对这个图像 x 进行了分类。”
-
将陈述转换为电路(算术化):不同的电路构建方法包括 R 1 CS、QAP、Plonkish 等。
与其他用例相比,ZKML 需要一个额外的步骤,称为量化。神经网络推断通常使用浮点算术完成,而在算术电路的主要领域中模拟浮点算术非常昂贵。不同的量化方法在精度和设备要求之间取得折衷。一些像 R 1 CS 这样的电路构建方法对神经网络来说效率不高。这部分可以调整以提高性能。
-
生成一个证明密钥和一个验证密钥
-
创建一个见证:当 w=w*时,f(x, w)=true
-
创建一个哈希承诺:见证人 w*承诺使用加密哈希函数生成一个哈希值。这个哈希值可以公之于众。
这有助于确保在计算过程中,私有输入或模型参数没有被篡改或修改。这一步至关重要,因为即使是细微的修改也可能对模型的行为和输出产生重大影响。
-
生成证明:不同的证明系统使用不同的证明生成算法。
需要为机器学习操作设计特殊的零知识规则,如矩阵乘法和卷积层,以便实现这些计算的子线性时间高效协议。
✓ 像 groth 16 这样的通用 zkSNARK 系统可能无法有效处理神经网络,因为计算负载过大。
✓ 自 2020 年以来,许多新的 ZK 证明系统应运而生,以优化模型推理过程的 ZK 证明,包括 vCNN、ZEN、ZKCNN 和 pvCNN。然而,它们中的大多数都针对 CNN 模型进行了优化。它们只能应用于一些主要的数据集,如 MNIST 或 CIFAR-10 。
✓ 2022 年,Daniel Kang Tatsunori Hashimoto、Ion Stoica 和 Yi Sun( Axiom 创始人)提出了一种基于 Halo 2 的新证明方案,首次实现了对 ImageNet 数据集的 ZK 证明生成。他们的优化主要集中在算术化部分,具有用于非线性的新颖查找参数和跨层重用子电路。
✓ Modulus Labs 正在为链上推理对不同证明系统进行基准测试,发现在证明时间方面,ZKCNN 和 plonky 2 表现最佳;在峰值证明者内存使用方面,ZKCNN 和 halo 2 表现良好;而 plonky 虽然表现良好,但牺牲了内存消耗,而且 ZKCNN 仅适用于 CNN 模型。它还正在开发一个专门为 ZKML 设计的新 zkSNARK 系统,以及一个新的虚拟机。
-
验证证明:验证者使用验证密钥进行验证,无需知道见证人的知识。

因此,我们可以证明将零知识技术应用于机器学习模型可以解决很多信任问题。使用交互式验证的类似技术可以达到类似的效果,但会在验证者方面需要更多资源,并可能面临更多的隐私问题。值得注意的是,根据具体的模型,为它们生成证明可能需要时间和资源,因此在将此技术最终应用于现实世界的用例时,各方面将存在折衷。
当前解决方案的现状
接下来,现有的解决方案是什么?请注意,模型提供者可能有很多不想生成 ZKML 证明的原因。对于那些勇敢尝试 ZKML 并且解决方案有意义的人,他们可以根据模型和输入所在的位置选择几种不同的解决方案:
-
如果输入数据在链上,可以考虑使用 Axiom 作为解决方案:
Axiom 正在为以太坊构建一个零知识协处理器,以改善用户对区块链数据的访问并提供更复杂数字化的链上数据视图。在链上数据上进行可靠的机器学习计算是可行的:
首先,Axiom 通过在其智能合约 AxiomV 0 中存储以太坊区块哈希的默克尔根来导入链上数据,这些数据通过 ZK-SNARK 验证过程进行无信任验证。然后,AxiomV 0 StoragePf 合约允许对 AxiomV 0 中缓存的区块哈希给出的信任根进行任意历史以太坊存储证明的批量验证。
接下来,可以从导入的历史数据中提取机器学习输入数据。
然后,Axiom 可以在顶部应用经过验证的机器学习操作;使用经过优化的 halo 2 作为后端来验证每个计算部分的有效性。
最后,Axiom 会附上每个查询结果的 zk 证明,并且 Axiom 智能合约会验证 zk 证明。任何想要证明的相关方都可以从智能合约中访问它。
-
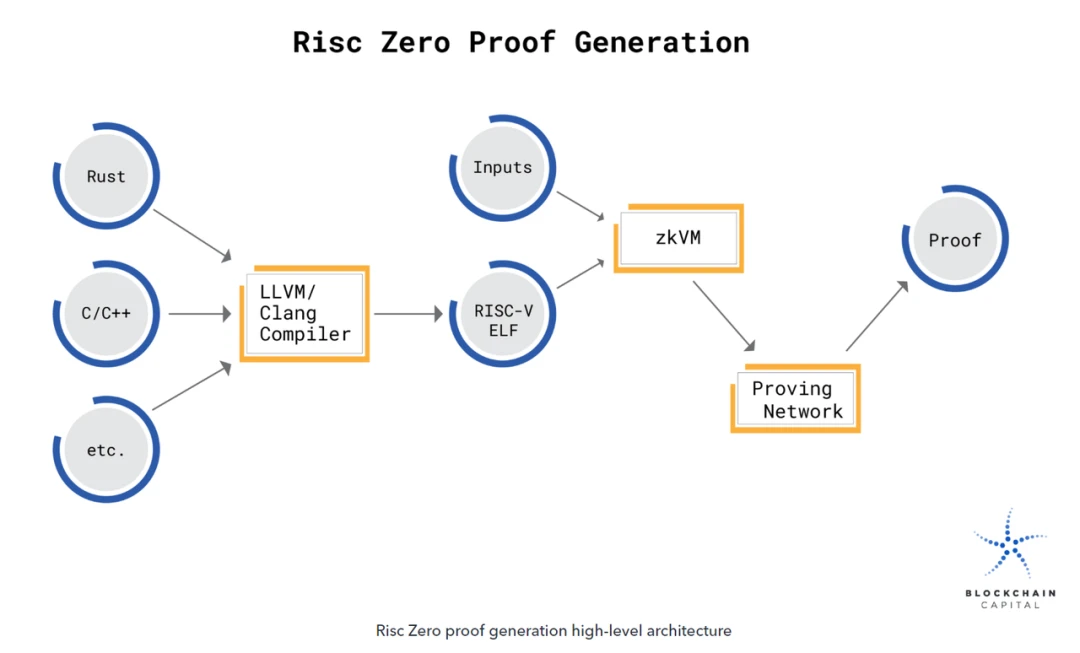
如果将模型放在链上,可以考虑使用 RISC Zero 作为解决方案:
首先,需要将模型的源代码编译成 RISC-V 二进制文件。当这个二进制文件在 ZKVM 中执行时,输出会与一个包含加密密封的计算收据配对。这个密封作为计算完整性的零知识论据,将加密的 imageID(识别执行的 RISC-V 二进制文件)与声明的代码输出关联起来,以便第三方快速验证。
当模型在 ZKVM 中执行时,关于状态更改的计算完全在 VM 内部完成。它不会向外部泄露有关模型内部状态的任何信息。
一旦模型执行完毕,生成的密封就成为计算完整性的零知识证明。 RISC Zero ZKVM 是一个 RISC-V 虚拟机,它可以生成对其执行的代码的零知识证明。使用 ZKVM,可以生成一个加密收据,任何人都可以验证这个收据是由 ZKVM 的客户代码生成的。发布收据时,不会泄露有关代码执行的其他信息(例如,所提供的输入)。
通过在 RISC Zero 的 ZKVM 中运行机器学习模型,可以证明模型涉及的确切计算是正确执行的。计算和验证过程可以在用户喜欢的环境中离线完成,或者在 Bonsai Network 中完成,Bonsai Network 是一个通用的 roll-up。
生成 ZK 证明的具体过程涉及到一个与随机 oracle 作为验证者的交互协议。RISC Zero 收据上的密封本质上就是这个交互协议的记录。
-
如果您想直接从常用的机器学习软件(如 Tensorflow 或 Pytorch)导入模型,可以考虑使用 ezkl 作为解决方案:
首先,将最终模型导出为 .onnx 文件,将一些样本输入导出为 .json 文件。
然后,将 ezkl 指向 .onnx 和 .json 文件,以生成可以证明 ZKML 语句的 ZK-SNARK 电路。
Ezkl 是一个库和命令行工具,用于在 zkSNARK 中进行深度学习模型和其他计算图的推断。
看起来简单,对吧?Ezkl 的目标是提供一个抽象层,允许在 Halo 2 电路中调用和布局高级操作。Ezkl 抽象了许多复杂性,同时保持了令人难以置信的灵活性。他们的量化模型具有自动量化的缩放因子。他们支持灵活地更改为新解决方案所涉及的其他证明系统。他们还支持多种类型的虚拟机,包括 EVM 和 WASM。
关于证明系统,ezkl 通过聚合证明(通过中介将难以验证的证明转换为易于验证的证明)和递归(可以解决内存问题,但难以适应 halo 2)来定制 halo 2 电路。Ezkl 还通过融合和抽象(可以通过高级证明减少开销)来优化整个过程。
-
值得注意的是,与其他通用 zkml 项目相比,Accessor Labs 专注于为完全上链游戏提供专门设计的 zkml 工具,可能涉及 AI NPC、游戏玩法的自动更新、涉及自然语言的游戏界面等。
用例在哪里
通过 ZK 技术解决机器学习的信任问题意味着它现在可以应用于更多“高风险”和“高度确定性”的用例,而不仅仅是与人们的对话保持同步或将猫的图片与狗的图片区分开来。Web3 已经在探索许多这样的用例。这并非巧合,因为大多数 Web3 应用程序都在区块链上运行或打算在区块链上运行,这是因为区块链具有特定的特性,可以安全运行,难以篡改,并具有确定性计算。一个可验证的行为良好的 AI 应该是能够在无信任和去中心化的环境中进行活动的 AI,对吧?
Web3中可应用 ZK+ML 的用例
许多Web3应用为了安全性和去中心化而牺牲了用户体验,因为这显然是它们的优先事项,而基础设施的局限性也存在。AI/ML 有潜力丰富用户体验,这无疑是有帮助的,但以前在不妥协的情况下似乎是不可能的。现在,多亏了 ZK,我们可以舒适地看到 AI/ML 与Web3应用的结合,而不会在安全性和去中心化方面做太多牺牲。
从本质上讲,这将是一个Web3应用程序(在撰写本文时可能存在或不存在),以无需信任的方式实现 ML/AI。在无需信任的方式下,我们指的是它是否在无需信任的环境/平台上运行,或者其操作是否可以被证明是可验证的。请注意,并非所有 ML/AI 用例(即使在Web3中)都需要或更喜欢以无需信任的方式运行。我们将分析在各种Web3领域中使用的 ML 功能的每个部分。然后,我们将确定需要 ZKML 的部分,通常是人们愿意为证明支付额外费用的高价值部分。下面提到的大多数用例/应用仍处于实验研究阶段。因此,它们距离实际采用还很遥远。我们稍后会讨论原因。
Defi 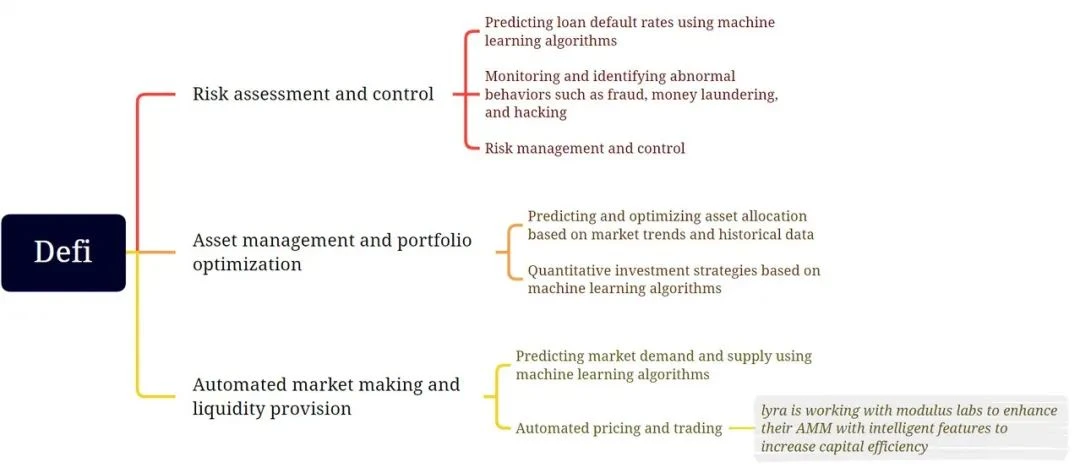
-
风险评估:现代金融需要 AI/ML 模型进行各种风险评估,从防止欺诈和洗钱到发放无担保贷款。确保这种 AI/ML 模型以可验证的方式运行意味着我们可以防止它们被操纵以实现审查制度,从而阻碍使用 Defi 产品的无需许可的性质。
-
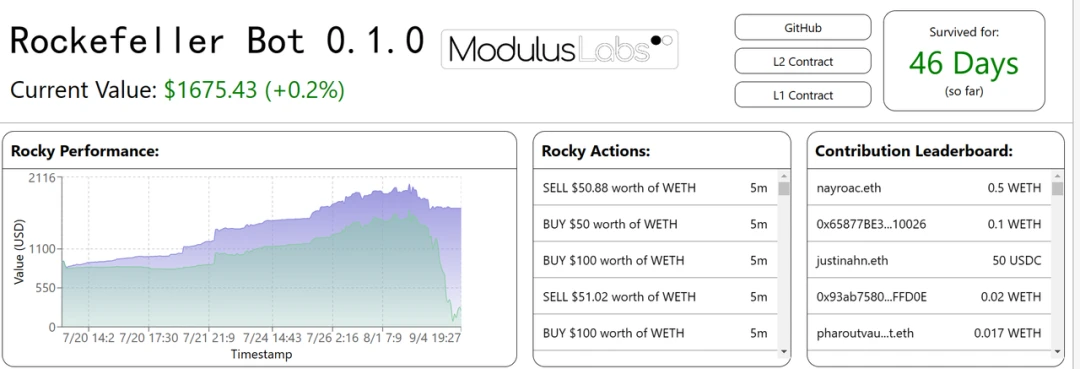
资产管理:自动交易策略对于传统金融和 Defi 来说并不新鲜。已经有人尝试应用 AI/ML 生成的交易策略,但只有少数去中心化的策略取得了成功。目前 Defi 领域的典型应用包括 Modulus Labs 实验的 Rocky Bot。
一个在 L1 上持有资金并在 Uniswap 上交换 WEth / USDC 的合约。
一个 L2 合约实现了一个简单(但灵活)的三层神经网络,用于预测未来的 WEth 价格。合约使用历史 WETH 价格信息作为输入。
一个简单的前端用于可视化以及用于训练回归器和分类器的 PyTorch 代码。
这适用于 ML 信任框架的“输出”部分。输出是在 L2 上生成的,传输到 L1,并用于执行。在此过程中,不会被篡改。
这适用于“输入”和“模型”部分。历史价格信息输入来自区块链。模型的执行是在 CairoVM(一种 ZKVM)中计算的,其执行跟踪将生成一个用于验证的 ZK 证明。
Rocky Bot:Modulus Labs 在 StarkNet 上使用 AI 进行决策创建了一个交易机器人。
-
Automated MM and liquidity provision:
本质上,这是风险评估和资产管理中进行的类似努力的结合,只是在交易量、时间线和资产类型方面采用了不同的方式。关于如何在股票市场中使用 ML 进行做市的研究论文有很多。在一些研究成果适用于 Defi 产品可能只是时间问题。
例如, Lyra Finance 正与 Modulus Labs 合作,通过智能功能提升其 AMM,使其资本利用效率更高。
-
荣誉提名:
Warp.cc 团队开发了一个教程项目,介绍如何部署一个运行训练好的神经网络以预测比特币价格的智能合约。这符合我们框架的“输入”和“模型”部分,因为输入使用 RedStone Oracles 提供的数据,模型作为一个 Warp 智能合约在 Arweave 上执行。
这是第一次迭代并涉及 ZK,所以它属于我们的荣誉提名,但是在未来,Warp 团队考虑实现一个 ZK 部分。
游戏
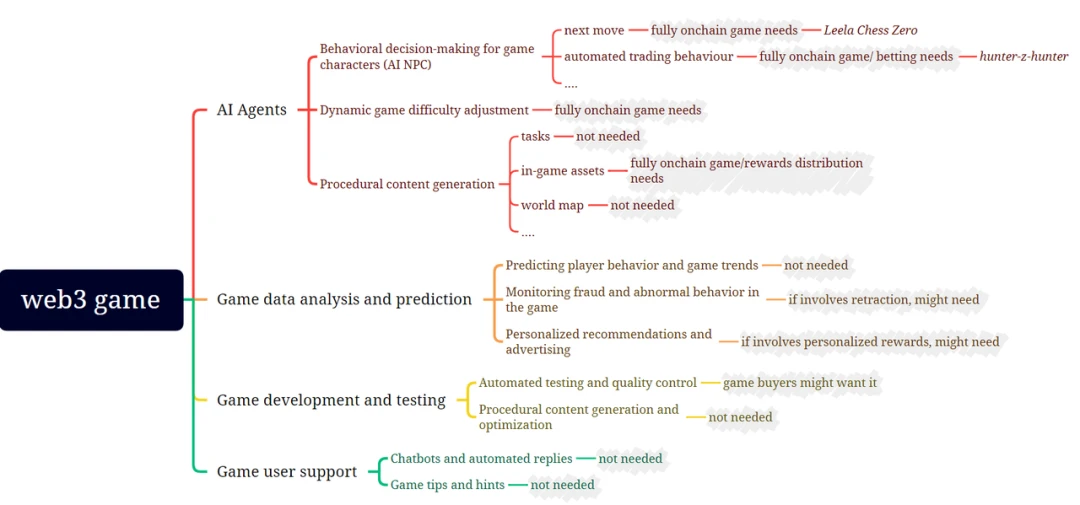
游戏与机器学习有很多交集:图中的灰色区域代表了我们对游戏部分中的机器学习功能是否需要与相应的 ZKML 证明配对的初步评估。Leela Chess Zero 是将 ZKML 应用于游戏的一个非常有趣的例子:
-
AI 代理
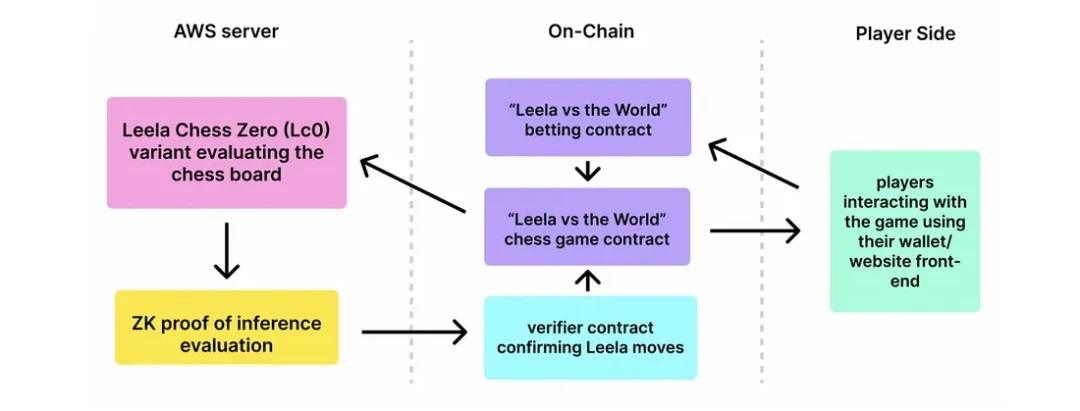
LC 0 和人类集体轮流进行游戏(正如象棋中应有的那样)。
LC 0 的移动是通过简化的、适合电路的 LC 0 模型计算出来的。
Leela Chess Zero (LC 0):由 Modulus Labs 构建的一款完全基于链上的 AI 棋手,与来自社区的一群人类玩家对战。
LC 0 的移动有一个 Halo 2 snark 证明,以确保没有人类智囊团的干预。只有简化的 LC 0 模型在那里做决策。
这符合“模型”部分。模型的执行有一个 ZK 证明, 以验证计算没有被篡改。
-
数据分析与预测: 这一直是 Web2 游戏世界中 AI/ML 的常见用途。然而,我们发现在这个 ML 过程中实现 ZK 的理由非常少。为了不让过多的价值直接涉及到这个过程,这可能不值得付出努力。然而,如果某些分析和预测被用来为用户确定奖励,那么 ZK 可能会被实施以确保结果是正确的。
-
荣誉提名:
AI Arena 是一款以太坊原生游戏,来自世界各地的玩家可以在其中设计、训练和战斗由人工神经网络驱动的 NFT 角色。来自世界各地的才华横溢的研究人员竞相创建最佳机器学习(ML)模型来参与游戏战斗。AI Arena 主要关注前馈神经网络。总体而言,它们的计算开销比卷积神经网络(CNNs)或循环神经网络(RNNs)低。尽管如此,目前模型只在训练完成后上传到平台,因此值得一提。
GiroGiro.AI 正在构建一个 AI 工具包,使大众能够为个人或商业用途创建人工智能。用户可以根据直观且自动化的 AI 工作流平台创建各种类型的 AI 系统。只需输入少量数据和选择算法(或用于改进的模型),用户就可以生成并利用心中的 AI 模型。尽管该项目处于非常早期阶段,但我们非常期待看到 GiroGiro 可以为游戏金融和元宇宙为重点的产品带来什么,因此将其列为荣誉提名。
DID 和社交
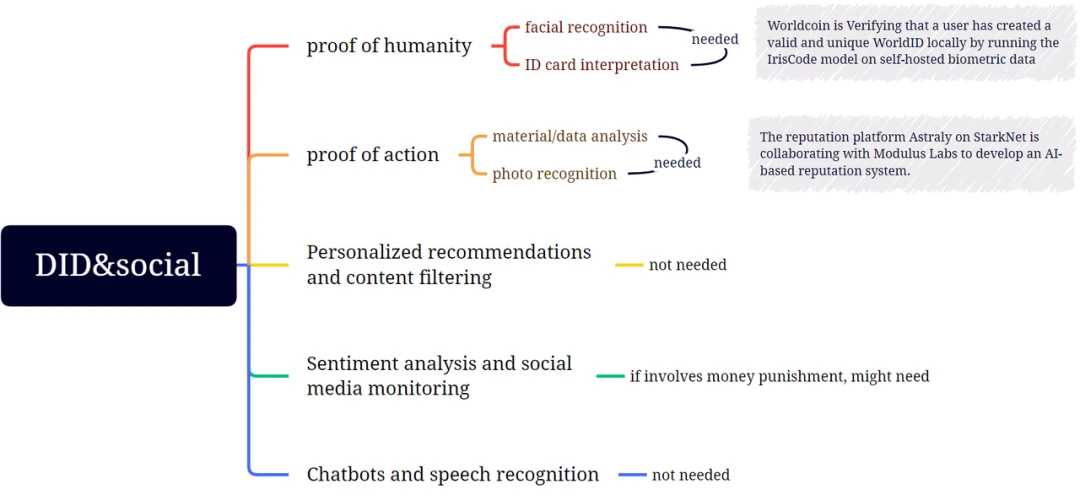
在 DID 和社交领域,Web3 和 ML 的交叉点目前主要体现在人类证明和凭据证明领域;其他部分可能会发展,但需要更长的时间。
-
人类证明
用户的应用程序在本地生成一个钱包地址。
应用程序使用 Semaphore 证明它拥有之前注册的一个公钥的私钥。因为这是零知识证明,所以它不会透露是哪个公钥。
证明再次发送到顺序器,顺序器验证证明并启动将代币存入提供的钱包地址的过程。所谓的零件随证明一起发送,确保用户不能领取两次奖励。
用户在手机上生成一个 Semaphore 密钥对,并通过二维码向 Orb 提供哈希后的公钥。
Orb 扫描用户的虹膜并在本地计算用户的 IrisHash。然后,它将包含哈希公钥和 IrisHash 的签名消息发送到注册顺序节点。
顺序节点验证 Orb 的签名,然后检查 IrisHash 是否与数据库中已有的匹配。如果唯一性检查通过,IrisHash 和公钥将被保存。
Worldcoin 使用一种名为 Orb 的设备来判断某人是否是一个真实存在的人,而不是试图欺诈验证。它通过各种摄像头传感器和机器学习模型分析面部和虹膜特征来实现这一目标。一旦做出这个判断,Orb 就会拍摄一组人的虹膜照片,并使用多个机器学习模型和其他计算机视觉技术创建虹膜编码,这是一个表示个体虹膜图案最重要特征的数字表示。具体的注册步骤如下:
Worldcoin 使用开源的 Semaphore 零知识证明系统将 IrisHash 的唯一性转换为用户帐户的唯一性,而不会将它们关联起来。这确保新注册的用户可以成功领取他/她的 WorldCoins。步骤如下:
WorldCoin 使用 ZK 技术确保其 ML 模型的输出不会泄露用户的个人数据,因为它们之间没有关联。在这种情况下,它属于我们信任框架的“输出”部分,因为它确保了输出以期望的方式传输和使用,在这种情况下是私密的。
从用例角度重新审视 ML 信任框架
可以看到,Web3 中 ZKML 的潜在用例尚处于起步阶段,但不能被忽视;未来,随着 ZKML 使用的不断扩大,可能会出现对 ZKML 提供商的需求,形成下图中的闭环: 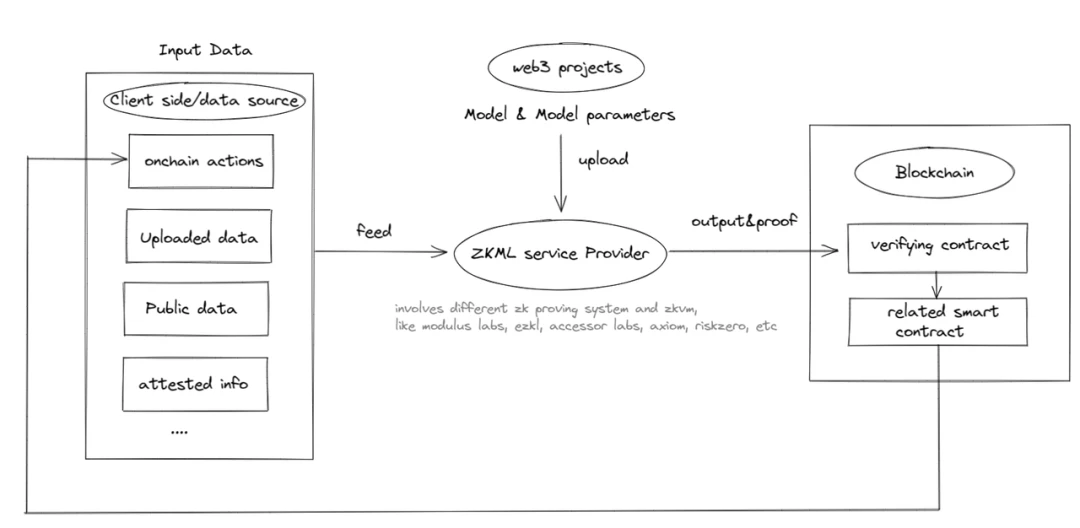
大规模应用还有多远?
最后,我们可以关注一下 ZKML 的当前可行性状态,以及我们离 ZKML 大规模应用还有多远。
Modulus Labs 的论文通过测试 Worldcoin(具有严格的精度和内存要求)和 AI Arena(具有成本效益和时间要求)为我们提供了一些关于 ZKML 应用可行性的数据和见解: 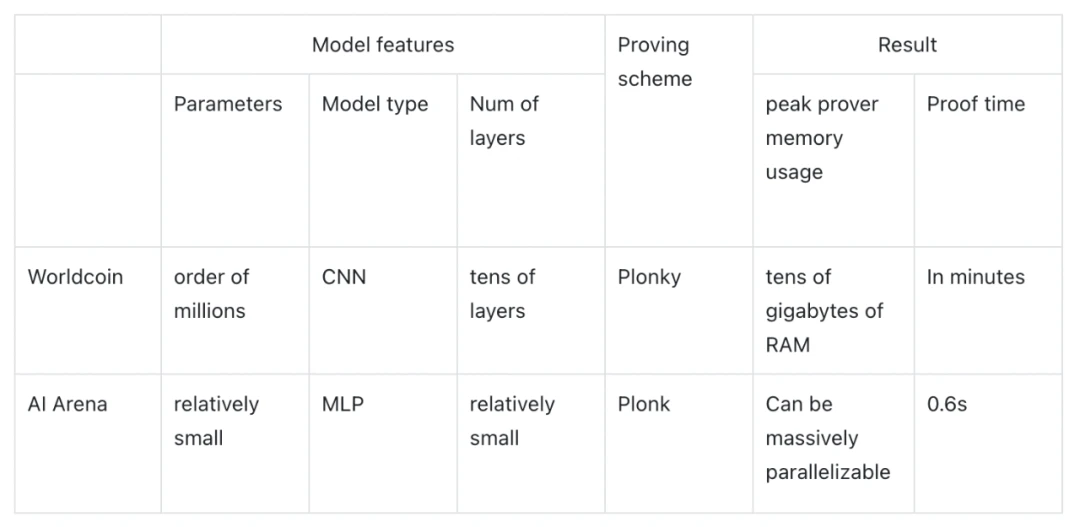

那么证明大小和验证时间呢?我们可以参考 Daniel Kang、Tatsunori Hashimoto、Ion Stoica 和 Yi Sun 的论文。如下所示,他们的 DNN 推理解决方案在 ImageNet(模型类型:DCNN, 16 层, 3.4 百万参数)上的准确率可以达到 79% ,同时验证时间仅需 10 秒,证明大小为 5952 字节。此外,zkSNARKs 可以缩小到 59% 准确率时验证时间仅需 0.7 秒。这些结果表明,在证明大小和验证时间方面,对 ImageNet 规模的模型进行 zkSNARKing 是可行的。目前主要的技术瓶颈在于证明时间和内存消耗。在 web3 案例中应用 ZKML 在技术上尚不可行。ZKML 是否有潜力赶上 AI 的发展呢?我们可以比较几个经验数据:
-
机器学习模型的发展速度: 2019 年发布的 GPT-1 模型具有 1.5 亿个参数,而 2020 年发布的最新 GPT-3 模型具有 1, 750 亿个参数,仅两年间参数数量增加了 1, 166 倍。
-
零知识系统的优化速度:零知识系统的性能增长基本上遵循“摩尔定律”式的步伐。几乎每年都会出现新的零知识系统,我们预计证明者性能的快速增长在一段时间内还将继续。
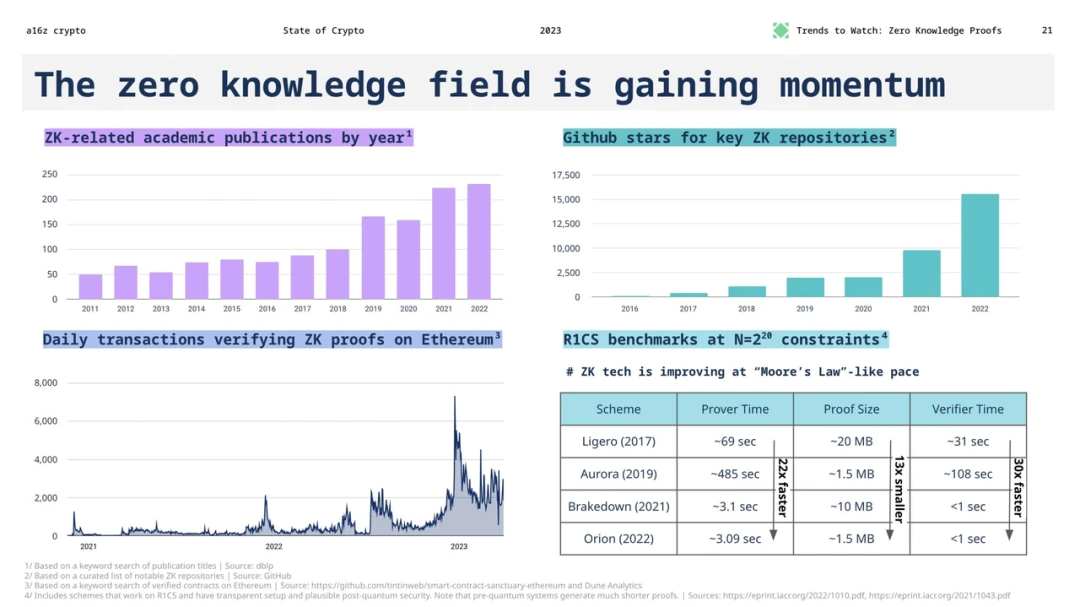
从这些数据来看,尽管机器学习模型的发展速度非常快,但零知识证明系统的优化速度也在稳步提升。在未来一段时间内,ZKML 可能仍有机会逐步赶上 AI 的发展,但它需要不断地进行技术创新和优化以缩小差距。这意味着,尽管目前 ZKML 在 web3 应用中存在技术瓶颈,但随着零知识证明技术的不断发展,我们仍有理由期待 ZKML 在未来能够在 web3 场景中发挥更大的作用。对比前沿的 ML 与 ZK 的改进率,前景并不十分乐观。不过,随着卷积性能、ZK 硬件的不断完善,以及基于高度结构化的神经网络操作而量身定做的 ZK 证明系统,希望 ZKML 的发展能够满足web3的需求,先从提供一些老式的机器学习功能开始。虽然我们可能很难用区块链+ZK 来验证 ChatGPT 反馈给我的信息是否可信,但我们也许可以在 ZK 电路中安装一些较小和较老的 ML 模型。
结论
"权力趋于腐败,而绝对的权力会使人绝对腐败"。随着人工智能和 ML 的令人难以置信的力量,目前还没有万无一失的方法将其置于治理之下。事实一再证明,政府要么提供后期干预的后遗症,要么提前彻底禁止。区块链+ZK 提供了为数不多的解决方案,能够以一种可证明和可核实的方式驯服野兽。
我们期待在 ZKML 领域看到更多的产品创新,ZK 和区块链为 AI/ML 的运行提供了一个安全和值得信赖的环境。我们也期待这些产品创新产生全新的商业模式,因为在无许可的加密货币世界里,我们不受这里的去 SaaS 商业化模式的限制。我们期待着支持更多的建设者,在这个 "西部荒野无政府状态 "和 "象牙塔精英 "的迷人重叠中,来建立他们令人兴奋的想法。我们仍处于早期阶段,但我们可能已经在拯救世界的路上。


