
读懂Arweave: Web 3的关键基础设施



文 | msfew、李沅琪
来源 | Foresight Ventures
1. 概览
Arweave 是一个专注于永久存储数据的去中心化网络. 相比比特币全球账本和以太坊全球计算机的定位, Arweave 类似一个永远不会丢失数据的全球硬盘. 在存储的公链中, Arweave 极有可能成为 Web3.0 的 "Layer 0", 作为一个重要的基础设施而存在.
2. 为什么永久存储数据很重要?
Web 前时代
Web 出现之前, 数据通常是通过史书等书本来记录的, 当时的图书馆是现在的存储中心. 在古代, 埃及的亚历山大图书馆是当时西方知识的源泉, 汇集了几十万卷珍贵的手抄书. 但是在几次战争之后, 亚历山大图书馆 600 年历史中积攒下来的图书就全部被烧毁. 这些珍贵的数据全部毁于一旦. 因为这些数据的烧毁, 人类历史进程很可能倒退了几十年.
Web 1.0 - Web 2.0 时代
在 Web2 时代里, 有一个和 Arweave 类似的网站: Internet Archive (https://archive.org). 它保存了几乎所有网站各时期的快照 (比如我们可以看到 01 年的苹果官网), 以及音乐, 书本等数据. 它就是 Web2 时期的永久存储, 保存了所有珍贵的网站和媒体等数据, 能在互联网高速的变化后看到它最初的样子. 但是它是由中心化数据库和服务器来运行的. 在笔者写下这段的时候, Internet Archive 的网站快照服务无法访问, 因此它的服务是比较不稳定的. 同时, Internet Archive 背后的组织需要支付大量的资金去维护服务器和数据库等, 这又是一个不稳定因素. 同时, 尽管 Internet Archive 背后是一个开源的非盈利组织, 但存储在它们服务器上的数据毕竟还是它们的, 有中心化的问题. 因为这些因素, Internet Archive 虽然肯定做了容灾备份等操作, 但还是有可能会在极端条件下丢失数据.
Web 3.0 时代
在 Web3 时代, Arweave 的出现带来了一个完美的解决方案. 通过独特的共识机制来保证数据的永久存储. 通过代币经济和合理挖矿机制来让矿工存储数据以及拓展和激活开发者生态, 解决了服务器和开发的资金问题. 通过去中心化的架构, 保证了用户的数据主权. Arweave 同时也持续在和 Internet Archive 积极合作, 把数据慢慢永久保存上链. Arweave 就是 Web3 时代, 永久存储数据的亚历山大图书馆.
3. 数据结构与共识机制
Arweave 通过 Blockweave 数据结构和 SPoRA 共识机制实现了文件永久存储的功能.
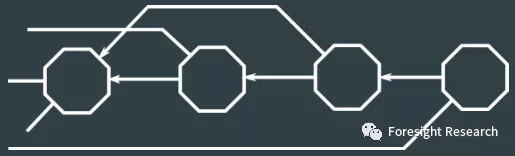
a. 区块坊 (Blockweave)
Arweave 与传统区块链的区块结构不同. 传统区块链的区块是不断接连着上一个, 因此形成了一条链式的结构. Arweave 在这个基础上, 还指向了一个随机的先前回忆区块 (之前叫 recall block, 现在叫 recall chunk) , 因此从三维的角度来看就是一个纺状的结构. 从存储内容来看,常规链上存储以索引为主,数据分布式存储于节点当中,而Blockweave的区块里存储了数据信息,可以从Arweave 的区块链浏览器上看到图片type等内容. Blockweave 这样的设计其实是自带分片属性的, 性能的可拓展性极强. 与其他存储项目相比, Arweave可以将TPS提高很多倍,并大大降低长期存储成本.
Blockweave 的设计最重要的还是服务于 Arweave 的共识机制.
 b. SPoRA 共识机制
b. SPoRA 共识机制
在讲解 Arweave 现在所使用的 SPoRA 共识机制之前, 我们可以先了解它之前所采用的 PoA + PoW 机制. PoW 机制我们已经很熟悉, 并且在很多区块链上我们都看到过 PoW 这个经典机制. 所以我们来着重看一下额外的 PoA 机制.
PoA 代表了 Proof of Access, 访问证明. 如果矿工想要生成新的区块, 那么就必须访问随机的一个回忆区块. 我们可以重新回想一下 Blockweave 的数据结构. 在理想的情况下, 如果矿工想满足这个 PoA 机制的条件, 那么他会去选择存储所有区块的数据, 因为每个下一个区块会指向当前区块以及之前随机的一个区块. PoA 激励了矿工去多存储 Arweave 的区块, 并且这也鼓励矿工去存储一些不被存储的区块, 来提高满足 PoA 的概率. 当然单单的 PoA 是不可行的, 因为如果大家都把所有数据存储了, 那么每个人的出块概率都是 1 . 所以在 PoA 之外还有 PoW 机制来保证去中心化. PoA 与 PoW 共识下, 矿工的出块概率 = 拥有随机回忆区块的概率 * 第一个找到 hash 的概率. 这样 PoA 独特的设计激励了矿工去多存储数据, 并且存储稀有的数据, 实现了数据的永久存储.
另外为了调节网络中块的生成速度, PoW 算法允许调整难度, PoW 难度越大, 计算周期越久, 如果网络中块的生成速率超过目标频率, 则增加了未来块生成的 PoW 难题的难度; 同样, 随着网络中块生成速度的降低, 难度设置也将向下调整; 通过这种方式, 网络能够调节区块生成率, 而不会受限于网络中的节点数量和算力影响.
在 PoA 的共识机制基础上, Arweave 在今年上半年把 PoA 升级到了 SPoRA (Succinct Proofs of Random Access). 单纯 PoA + PoW 的机制只是在数据的永久存储上达到了目的, 但是在数据的访问速度上没有做到激励, 所以矿工很可能把数据库放在成本更低的其他地区, 而并非本地. 这样会导致由于距离等因素造成的网络访问速度变慢. SPoRA 的机制降低了之前矿工出块概率中的权重, 加入了对数据访问速度的考量. PoW 在出块概率中的权重下降, 使得在寻找 hash 中浪费的算力和能源大大减少, 降低了能耗, 对环境更加友好. 将 PoA 升级成了 SPoRA 让矿工更加专注于维护自己本地的硬件和节点, 避免矿工们都把数据存储在同一个费率低的数据中心, 做到节点地理位置的多样化, 和更强的去中心化.
通过这些设计独特且巧妙的共识机制, Arweave 保证了数据的永久存储, 访问速度和爆块时间.
c. 去中心化存储
Arweave 的另一大特性就是矿工的体验非常良好. 相对于传统的区块链, Arweave 不需要矿工下载整个区块链所有节点的数据, 而是只需要下载几个区块就可以开始挖矿 (虽然这个时候出块的概率很低). 这其实是非常重要的一点. 如果作为一个存储的链, 而没有这样的设计的话, 那新节点的加入是特别困难的.
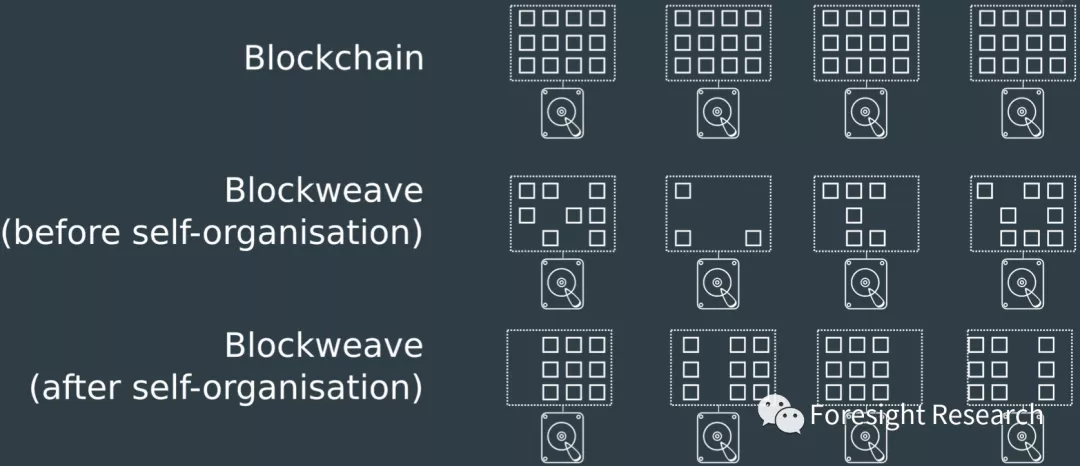
通过区块纺以及共识机制的设计, 矿工们会自发地去下载稀有的数据 , 这就会保证数据的平均存储个数保持统一. 下图第一行展现了传统区块链的各个节点. 各个节点需要下载所有的数据, 这浪费了很多资源. 第二行表示了矿工自发下载稀有数据之前的情况, 稀有数据有可能被矿工所遗漏, 导致了数据可能的丢失, 并且部分数据的过多存储. 而第三行则是 Arweave 现在的情况, 表示了矿工在自发下载稀有数据后达成的平衡情况. 每份数据都有相同数量的拷贝, 在最大化数据存储安全性的情况下, 避免了资源的浪费.
4. 网络与应用架构
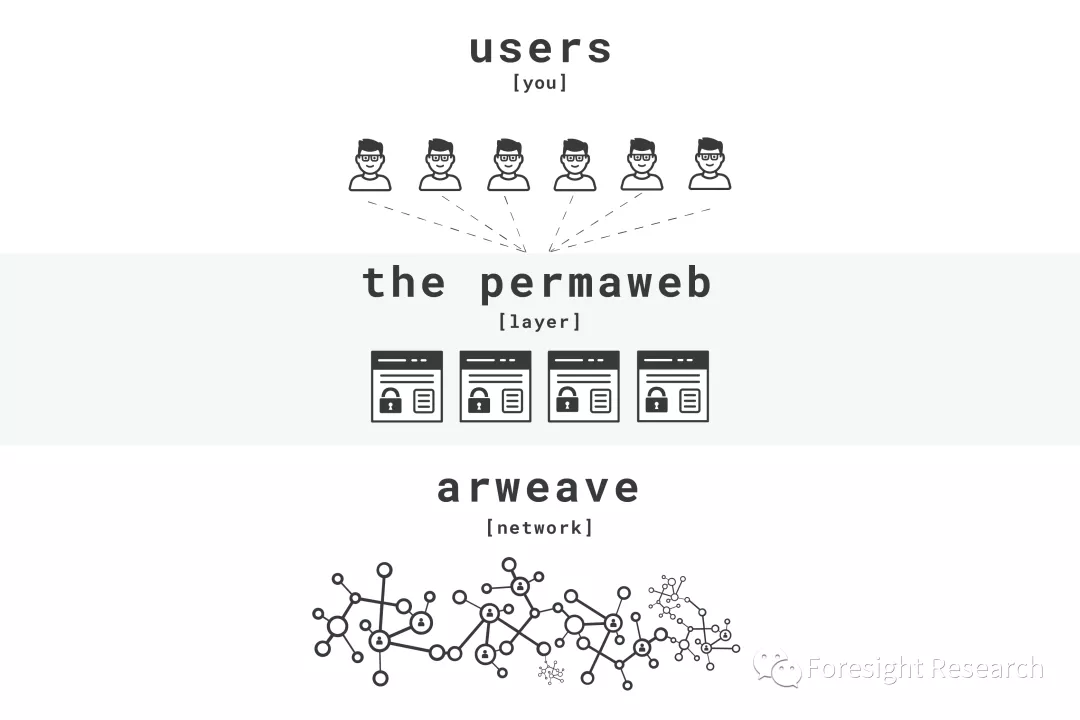
Arweave 这样的架构给开发者提供了极高的自由度. 就和 Web2.0 时代一样, 一个应用程序的后端使用 PHP 还是 Java 都无所谓, 任何的开发者在熟悉 Arweave 的 HTTP API 以后 (对开发者来说学习成本几乎为0) 都可以将 Arweave 作为区块链数据库, 以 基于存储的共识范式 来开发出自己的去中心化应用. 基于存储的共识范式 (SCP) 是一种智能合约设计思路, 给 Arweave 带来了无限的生态潜力.
但这样的开发灵活度带来的问题是, 由于 DApp 不是运行在 Arweave 上的, Arweave 没法直接规定 DApp 的合约与代币标准. 我们将在后面一节中具体探讨 Arweave 智能合约的内容.
DApp = 前端页面 = 智能合约
- 智能合约的定义
- 根据 Nick Szabos 在 1996 年创造"智能合约"一词时, 他定义智能合约应该有以下四个特点: 一组承诺; 以数字形式指定,并非纸质; 包含协定; 合约涉及到的人员履行承诺. 除此之外, 我认为智能合约还需要做到数据存储可信和计算可信的特点.
- 传统 DApp 与 Arweave DApp
- 一个传统的 DApp 通常包含了应用的前端 (网页) 和智能合约. 应用的前端将用户的数据传送到智能合约. 这样的 DApp 满足了智能合约的四个条件和两个特点. Arweave 的开发者是这样认为 Arweave 的 DApp 和智能合约的: 前端页面就是智能合约 . 思路是: 一个 DApp 不用同时拥有前端页面和链上的智能合约, 而是只要把前端页面和智能合约合二为一就可以.
- 前端页面和智能合约是如何合二为一的?
- 在前文中, 我们提到了 Arweave 中是可以直接存储不同 content-type 的文件的. 我们可以把前端的页面直接存储到 Arweave 中, 打开这个交易数据时就直接可以看到一个完整的页面! (比如 这个交易 中存储的 数据, 点开就直接是一个渲染好的前端页面) 通过这个例子, 我们其实就可以了解了为什么前端页面可以是智能合约. 因为我们在打开 Arweave 代码数据的同时, 浏览器也为我们渲染好了页面. 我们不仅能看到页面的源码, 也能看到页面. 这在以太坊上是做不到的, 以太坊的智能合约在浏览器眼里只是一串文本, 浏览器是渲染不成页面的. 当开发者在开发的时候, DApp 的逻辑和合约的逻辑都可以写在前端里, 然后通过 HTTP API 来将需要存储的交易和数据存储到 Arweave 上.
- 如何保证数据存储可信和计算可信?
- Arweave 的生态开发者和 Sam Williams 所倾向于的共识是 基于数据的"共识" (由 Arweave 生态开发者, everFinance Founder outprog 首次提出). 合约的页面源码存储在 Arweave 上, 具备确定性, 我们可以随意查看. 同时每个交互的数据也存储在链上, 这就保证了数据的存储可信. 在我们渲染出合约页面的同时, 现代浏览器为我们提供了一个几乎完全统一的执行环境, 这就保证了计算可信. 通过这样的设计, Arweave 的智能合约同时保证数据永存/数据不可变/数据可追溯/数据成本低.
- 合约代码如何升级呢?
- 当想要升级合约或前端样式的时候, 开发者只需要重新发布一次新版的合约到 Arweave 上, 这就会生成一个新的 Arweave 交易, 更新前端页面以及合约内容.
智能合约的不同实现
- Smartweave (Arweave 作为图灵机的纸带, Smartweave 专用于管理图灵机的状态)
- 概览:
- 还记得我们在前文中提到的图灵机纸带概念吗? 要组成一个图灵机, 光有 Arweave 的纸带记录状态可不行, 我们还需要一个方式去有效的管理和改变应用的这些状态. Smartweave 所做的则是这缺少的重要一环. Smartweave 是 Arweave 官方所做的智能合约标准, 所使用的也是前端代码 = 智能合约的概念, 开发者可以使用 JavaScript 这门前端的脚本语言来管理状态. 前端页面其实本身就是各种 UI 的逻辑和状态, 相信对于前端开发者来说, 使用 Smartweave 来写智能合约去管理状态会比 Solidity 上手容易非常多.
- 设计思路与特点:
- Smartweave 的设计思路是 Lazy-execution, 不得不执行的时候再执行. 当用户在前端必须要得到最新合约状态的时候才会去执行. 因为使用的是 JavaScript 的语言, 所以用户在浏览器内就可以直接运行所有的交易, 不需要链上运行. Smartweave 会存储最初状态以及和合约相关的交易 (一个形如 [交易1, 交易2, 交易3] 的有序列表). 当要得到合约最新状态时, 用户会在浏览器中里运行所有合约相关的交易, 相当于用户自己作为一个节点, 最后得出最新状态, 然后提交新的交易.
- 实例分析:
- CommunityXYZ 是 Arweave 利润分享社区的仪表板和管理平台. CommunityXYZ 的 智能合约 是 Smartweave 的一个标准实现. 它使用了 TypeScript (相当于拓展版的 JavaScript ). 其中通过类似 JSON 的数据结构, 包含了用户的余额, vault, 角色, 投票情况等信息. 同时合约也实现了必需的 Transfer, increaseVault, 检查余额等功能. CommunityXYZ 所实现的 SmartWeave 合约完全可以放到前端页面代码库当中, 这样合约逻辑就可以保存在于前端当中.
- 缺点与优化:
- 如果仔细读 Smartweave 的设计思路, 你会发现这样的设计后, TPS 的上限成为了用户浏览器性能以及网络带宽上限. 但是, 将所有交易留给用户执行会出现一个问题, 如果一个合约的交易数量多了以后会不会造成一旦要得到最新状态, 就需要运行很久, 造成阻塞呢?
- 虽然在现实情况下, 正常但较多数量的交易不会造成很大的用户体验上的困扰 (现代网页中加载和运行的 JavaScript 文件大小其实是本身就很大的, 比如笔者正在使用的 notion.so 官网的 JavaScript 代码就有大约 2MB, 但是也是能够秒开 ), 但是如果遭到 DDoS 攻击, 有人上传非常多恶意交易数据 (比如几个 GB), 那么就肯定会有问题了. 为了解决这个问题, 我们可以在提交交易前, 通过一个另外的 Smartweave 合约过滤交易数据, 接收大量交易数据, 然后批量 rollup 到 AR 上.
- 同时, 开发者可以参考 Redstone 所实现的 Smartweave 合约. Redstone 通过浏览器多层缓存来减少不必要的交易数据的重复加载与运行, 可以大大优化客户端的合约性能. 或者由可信的用户来生成交易状态快照, 减少交易的运算.
- everFinance 的 token-demo (另一种基于存储的共识计算范式)
- everFinance 所实现的 token-demo 与 Smartweave 的设计思路基本一致, 同样是基于 Arweave 作为图灵机的纸带这一思想. token-demo 包含了两个应用模块: issuer (代币发行运营程序) 和 detector (代币验钞机程序). 代币发行运营程序, 提供了 Token 的 WEB 端页面, 提供了查询余额, 交易记录, 和提交交易的代币接口. 代币验钞机程序, 运行后自动加载 Arweave 上的数据 (就和我们在 Smartweave 一节中描述的 Lazy-execution 一样), 提供接口查询代币交易情况.
理论上来说, Arweave 的智能合约可以用无数种不同的形式来实现, 因此每个项目可能都会有自己不同的实现, 但大多数项目都使用了 Smartweave. Arweave 实际上是有类似 ERC-20 这样的代币标准的, 指定了各种 API. Arweave 上 Smartweave 的智能合约极大地简化了开发流程, 如果使用 Arweave 进行存储, 项目组可能根本就不需要专门的合约工程师.
5. PSC (利润分享社区) 解读
PSC (利润分享社区) 介绍
PSC 是 Arweave 上的利润分享社区, 是初创项目一种新的、更公平的结构. 这些社区赋予创始人对其项目的更多主动控制权和灵活性, 同时赋予这些项目的贡献者更大的权力. 在传统的初创企业中, 员工拥有的股权不太可能很快变成流动性, 不会被授予治理权, 也几乎不会收到股息. 同时, PSC 将 DAO 和代币相结合. PSC 的投票权取决于一个人持有多少社区 PST, 以及他们持有这些代币的时间.
相比之下, 所有 PSC 贡献者都能赚取 PST 代币, 这些代币赋予他们公平的治理权, 即时流动性和使用应用程序产生的利息. 在利润共享社区的 Hub 上 communityXYZ 可以看到更多 PSC 的项目.
PST (利润分享代币) 介绍
PST 是一种额外的机制, Arweave 允许开发人员在创建协议时将协议所属代币附加 PST 属性, 用户在Arweave上与应用程序交互产生手续费时, PST 属性代币的持有者将从手续费中按照创建协议时约定的比例获得以 AR 代币的返还, 返还将以 PST 持有者的相对 PST 持有量比例随机分发, 持有的 PST 代币数量大, 相对应获得分配的几率高 (类似于 PoS ) , 此举相当于 Arweave 以手续费返还的方式激励协议做好用户基础, 项目开发者可以此做为重要收入来源, 持币者也可根据项目的发展情况获得除币价增幅外的分红收益.
PST 的开发
你可能会有疑问, 为什么这样的代币没有由 Arweave 来设计制定标准呢? 让项目设置是否安全呢? 其实 Arweave 上的 PST 也是有像 ERC20 一样的标准, 会有一些 state 的通用接口. 但是对于我们做应用, 其实是没有任何限制的, 开发者可以灵活的发挥 Smartweave 和 PST 的优势, 所以 Arweave 并没有强制推行标准. 关于放权给项目进行设置, 我们之前的篇幅中提到了 Arweave 的开发者普遍认为项目的前端就可以是智能合约. 那么如果这样的利润分配是写在合约里的, 那么其实就很安全了. 用户完全可以去查证代币是否正确分配, 保证了 Code is Law.
PST 是否能登陆中心化交易所?
从技术角度看,PST类型的代币是满足登陆中心化交易所条件的,但仍未见到他们身影的主要制约条件来自于以下两点:
一是Arweave生态整体处于早期状态, PST 代币的流动性和 PSC 的活跃度不佳. 在 PST 的去中心化交易所 Verto中, 所有 PST 代币本月只发生一笔交易. 并且比如 Evermore, 从 4 月发布以来, 价格就没有变动过, 体现了流动性的不佳. 但是如果登上交易所, 那么流动性的问题可能得以解决.
6.当前存储情况
节点分布情况
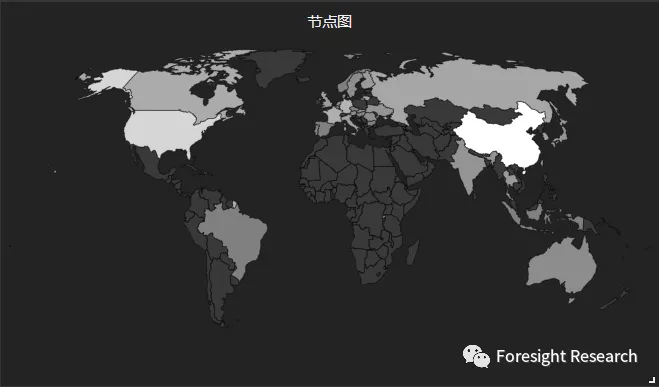
当前节点数量为1019个, 其中大陆地区节点数为868, 美国地区节点数为103, 其余零散分布在各个国家中, 当前节点数量仍较少, 且单节点存储上限较低, 但相比今年4月份时节点数量的150个, 已实现较大飞跃.
存储总量
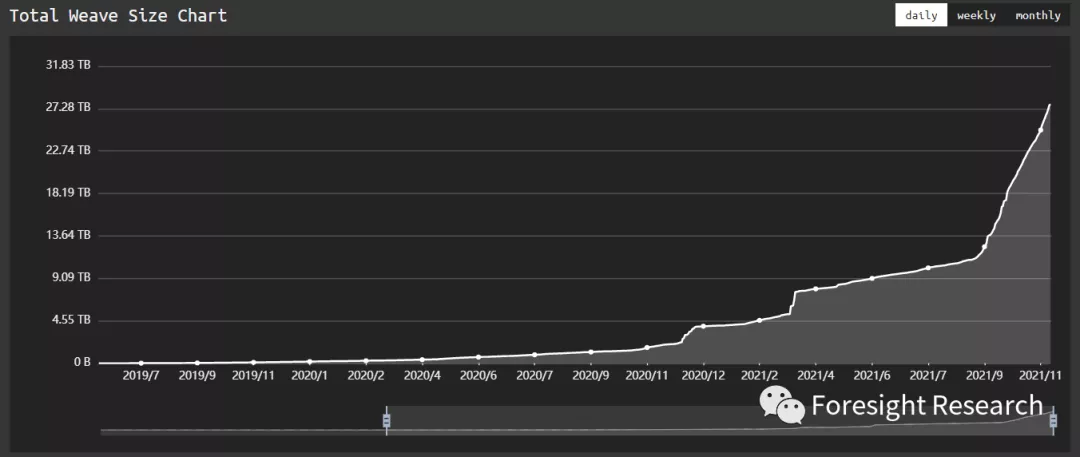
NFT 的爆火推动了 Arweave 的存储, 紧接着更多区块链将数据进行备份, 存储总量迅速攀升至 27.5TiB, 与 Filecoin 的存储总量 13.5EiB 相比, 存储量相差超 50 万倍, 但 Filecoin 因为其激励机制的问题导致其存储有效信息比例较低, 而 Arweave 单个区块即可上传 43.88GB 的数据.
存储价格
Arweave 共识成本较低, 1GB 数据 (可处理千万笔交易) 的永久存储只需要大约 20 美金. 相比之下, Filecoin 的用户存储成本大约在 0.06 美金 1GB, 但是 Filecoin 所提供的模式是按年计费的, 没有保证数据的永久存储, 并且 Arweave 是买断制, 一次付费可以保证至少存储 200 年. 因此 Arweave 在数据存储上有一些合理的溢价.
Arweave为保障提供给矿工的存储费用具备长期竞争力, 将目前用户支付的大部分交易费存放到捐赠基金, 将会随着其生态 DApp 的发展情况, 逐渐将交易费释放到矿工手中.
7. 网络项目生态
生态概览
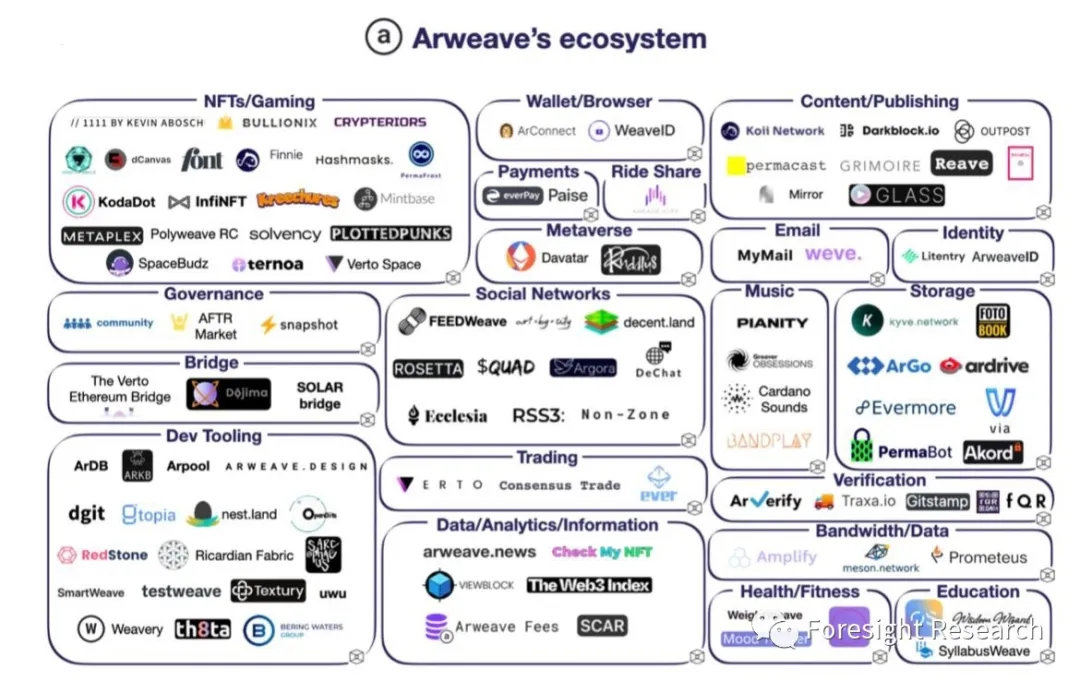 ArDrive
ArDrive
百度网盘是百度云的存储前端, 那相对应的 ArDrive 就是 Arweave 的存储前端. ArDrive 可以看作是存储在 Arweave 上的"百度网盘", 它是一套适用于 PC 端和移动端的应用程序, 可以将文字, 图片, 视频等各种形式数据上传至 Arweave, 进行永久化存储. 当前 ArDrive 是一次性付费可永久使用, 存储价格约为 1G 容量 20 美元, 比当前传统存储价格略高, 但其具备的永久存储和数据安全价值远超传统存储方式.
它面向的受众不单是币圈, 而是存储所有值得永久记录的美好.
KYVE
Arweave 存储的优越性使其受到了不同区块链的青睐, 而 KYVE network 可以看做是 Arweave 的跨链存储的中间层, 通过 KYVE 可以将其它区块链的数据永久存储在 Arweave 上做为备份, 不同区块链也可通过 KYVE 网络进行数据交互. 除此之外, KYVE 通过存储池的方式来保障上传数据的准确性, 上传者负责存储最新数据, 验证者确保上传数据的准确性, 双方通过向存储池质押 KYVE token 来保证准确及公正.
当前可从官网中得知其公链整合将覆盖 Avalanche, Cosmos, Near, Polkadot 以及 Solana.
EverPay
Everpay是一个用于跨链转账的DApp,当前已实现以太坊和Arweave上的实时代币转账,用户可以将以太坊或Arweave上的资产充值到Everpay中,通过映射的方式任意从另一端取出资产,且无需等待和无需Gas费,所以Everpay更像是一个Layer2应用,通过链下计算保障速度,将数据rollup到Arweave上保障安全,成为打通Arweave生态与其它区块链的通道。
未来Everpay将会承载和整合更多区块链,同时支持智能合约账户,为更多想要参与到Arweave发展红利的投资者提供无缝转移的优质体验。
Verto
文章上边讲过目前 PST 类型的代币还暂未登陆中心化交易所, 而 Verto 就是 PST 类型代币的去中心化交易所, 面对着 PST 代币的利润分享机制. Verto 更重要的作用是做为收益互换的工具, 既通过 Verto 持有流量大的协议以获得更高的手续费返还收入. 另外其代币VRT可以获得全部 PST 交易费用 0.5% 手续费抽成. 在今年 2 月份 Verto 完成以太坊桥接后, 允许用户通过 Verto 兑换 ETH 的同时允许 VRT 的持有者获得以以太坊计价的交易费.
虽然当前 Verto 的成交笔数极少, 但伴随着 Arweave 经济效应的增强, PST 类型代币的推广和 VRT 的价值捕获方式, Verto势必迎来其高光时刻.
ArConnect
如果想使用 Arweave, 那势必绕不开 ArConnect. 作为 Arweave 生态的第一款插件钱包, 结束了之前使用 DApp 需将密钥粘贴到应用页面的尴尬局面. 其目前已于 Arweave 生态深度绑定, 作为官方和众多协议的主推钱包, 值得一提的是目前尚不对程序内的 AR 和 PST 转账收取费用, 与 DApp 交互时产生的费用将会部分分配给随机选择 (POS) 的 VRT 代币持有者手中.
Pianity
由于 Arweave 生态整体处于早期范畴, 其上除基础设施类协议外, 王牌项目应当属 Pianity. 该项目为音乐 NFT 平台, 提出了一种可带给收藏者一定年化收益的模式, Pianity 平台通过音乐 NFT 的一级销售和二级交易获取一定手续费收入, 然后按照用户购买 NFT 时的价值和全体 NFT 总价值的比率将收益分配到每一个持有NFT的用户手中. 由于占比计算方式是购买 NFT 时的价格, 就可能导致用户为获得更高分配占比而刻意抬高 NFT 价格, 反向刺激市场可分配收益也逐渐增加, 吸引流量关注. 另外其代币 PIA 也同属 PST 类型, 故用户除可获得的 NFT 收益外也将获得 Pianity 流量的变现.
在音乐 NFT 的相对蓝海市场中, Pianity 通过永久存储和双收益模型, 有机会脱颖而出.
Arweave 是否需要智能合约和代币标准?
在我真正了解 Arweave 之前, 我一直认为一个公链的生态要发展起来就必须要智能合约和代币标准. 但是 Arweave 作为一个更加底层的链, DApp 并不是运行在链内部的, 肯定无法像以太坊一样在 EVM 这样的特定安全沙盒环境中限制住开发者. 但是其实 Arweave 开发者们的 "前端 = 智能合约", "基于存储的共识计算", 和 "Arweave 作为图灵机纸带" 的思想, 其实慢慢让开发者达成了共识, 所以越来越多的项目生态都在使用 Smartweave, 实施 "前端 = 智能合约" 的设计思路.
 8. 总结: Arweave 真正的价值会在 Web3.0 爆发.
8. 总结: Arweave 真正的价值会在 Web3.0 爆发.
我们可以先一一列数一下 Arweave 的优点.
Arweave 的独创共识和矿工激励机制保证了存储的永久性. 永久保存数据一直是人类历史上的重大问题, 对人类的重要性极其大. Arweave 可以作为 Web3.0 时代的亚历山大图书馆, 保存数据, 继续累积人类的智慧. Arweave 的去中心化特性可以颠覆中心化云服务厂商对存储市场的垄断, 用户的数据可以避免审查, 同时也让数据存储在云端, 带来了数据分发的自由. Arweave 的存储定位足够底层, 可以作为 "Layer0", 成为区块链开发无法缺少的一环, 并且用途广泛, 上手极其简单, 是各类去中心化应用的理想温床.
接下来我们看看 Arweave 的缺点.
Arweave 太过底层, 由于架构原因无法限制代币和合约的标准, 开发生态太过于灵活, 可能没法统一, 导致生态无法合力.
我们可能暂时看不懂 Arweave, 但是我们当初也没有看透比特币. 查理芒格说过: "为了节省运算空间, 人类的大脑会不愿意作出改变. 这是一种避免不一致性的形式." 我们不能以正常区块链的视角来看待 Arweave, 因为那样就错失了 Arweave 很多的重要价值. Web3.0 很可能会在2 年内到来, 到时候 Arweave 这样的区块链基础设施一定会展现自己的优点, 被所有人理解.


