
【共识专栏】共识的分类(上)



—— Part1 共识的分类 ——
从早期的分布式一致性算法的缓慢发展到现如今区块链共识的百花齐放,共识算法的发展已经走过了四十年左右的时光。 不同的共识算法的侧重点不同,因此它们所面临的问题、环境也不一样。 本文将从如下几个不同角度对共识算法进行分类:
▲容错类型
根据是否容忍拜占庭错误,可以将共识算法分为两类。
1)拜占庭容错共识算法:PBFT、 PoW 、 PoS 、DPoS
2)非拜占庭容错共识算法:Paxos、Raft
是否容忍拜占庭标志着该算法是否能够应用到低信任的网络当中。 通常来说,公有链环境中必须使用拜占庭容错算法,而联盟链 中可以根据联盟参与方之间的信任程度进行选择。
▲ 算法确定性
根据算法的确定性,可以将共识算法分为两类。
1)确定性共识算法:Paxos、Raft、PBFT
2)概率性共识算法:PoW、部分PoS
确定性共识指的是 共识决策一旦达成,就不存在回退的可能性 ,这一类通常是传统的分布式一致性算法及其改进版本。而概率性指的是已经达成的 共识决策在未来有一定的概率会被回退 ,虽然这个概率随着时间的推移会趋于为0,这一类通常是应用在公有链上的区块链共识算法。
▲ 选主策略
根据选主的策略,可以将共识算法分为两类。
1)选举类共识算法:Raft、PBFT
2)证明类共识算法:PoW、PoS
选举类共识指的是通过投票选择出块节点, 同一个节点可以连续多轮作为出块节点存在 ,这一类通常是传统的分布式一致性算法及其改进版本。证明类共识算法指的是 出块节点需要通过某种方式证明自己具备某种能力 ,从而获得出块权,这一类的共识算法通常每一轮的出块节点都不相同,从而保证了出块权的公平性,通常应用在公有链上。
—— Part2 非拜占庭容错共识算法 ——
Paxos
Paxos是 第一个异步网络模型下能够保证正确性且容错 的共识算法 。在此之前,FLP明确指出在异步网络模型中,只要存在节点故障,就不可能存在一个可终止的共识算法。因此Paxos也做出了一定的牺牲:Paxos牺牲了一定的活性从而保证了系统的 安全 性,即在系统处于异步状态时暂停共识的推进,只要有半数以上的节点恢复至同步状态之后,就可以推进共识,完成终止。
在Paxos中,会存在一个或者多个节点同时想要竞选成为 协调者 (也叫做提案者Proposer),而每一轮共识最终只会选出一个Proposer进行最终提案值的选择。Proposer提出一个决策值,并收集其他 参与者 节点(也叫做接受者Acceptor)的投票。最终,Proposer会宣布选定的最终决策值。如果能够达成一个最终决策的话,该决策值会被传递到对此感兴趣的节点(也叫做学习者Learner)中。可以看出,Paxos是一个保证了公平性的算法,即所有节点都可以竞选成为Proposer,没有哪个节点拥有特殊的权利。
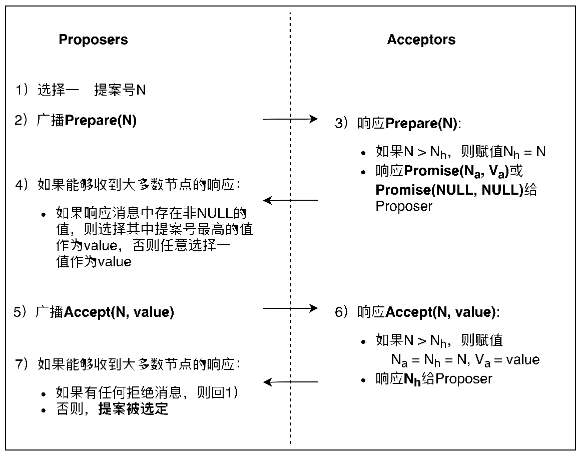
图1.Basic Paxos共识流程
Paxos在一定程度上给出了一种异步网络下分布式一致性问题的解决范式,但是它本身的算法过于 晦涩难懂,以至于Lamport本人也在Paxos发表之后又写了一篇论文[1]来重新解释Paxos的流程。同时,一个Paxos算法的正确实现也被证实是非常有难度的挑战,有兴趣的读者也可以阅读Google的实践论文[2]来理解实现过程中的一些权衡与考量。
Raft
Paxos诚然是一个非常有影响力的共识算法,可以说奠定了分布式一致性算法的基础,但是由于其难以理解以及实现难度非常之大,想要实现一个完整的Paxos算法非常的困难。因此,出现了非常多的Paxos变体,其中最著名的当属Raft共识算法。
Raft是一种用来管理日志复制的一致性算法,旨在易于理解。它具备了Paxos的容错性和性能,不同之处在于它将一致性问题分解为相对独立的三子问题,分别是领导选取(leader election),日志复制(log replication)和安全性(safety)。这使得Raft更好理解并且更容易应用到实际系统的建立中。
在Raft中,每一个节点一定会处于以下三种状态中的一个: Leader(主节点)、Candidate(候选节点)、Follower(从节点)。 在正常情况下,只有一个节点是Leader,剩下的节点是Follower。 Leader负责处理所有来自客户端的请求(如果一个客户端与Follower进行通信,Follower会将信息转发给Leader),生成日志数据(对应在区块链中即负责打包)并广播给Follower节点。 Follower是被动的: 他们不会主动发送任何请求,只能单向接收从Leader发来的日志数据。 Candidate是在选举下一任Leader的过程中出现的过渡状态,任何一个节点在发现主节点故障之后都可以成为Candidate并竞选成为Leader。
Raft算法将时间划分成为任意不同长度的 term (任期)。任期用连续的数字进行表示。每一个任期的开始都是一次选举。如果一个Candidate赢得了选举,它就会在该任期的剩余时间担任 Leader 。在某些情况下,选票会被瓜分,有可能没有选出Leader,那么,另一个任期将会开始,并且立刻开始下一次选举。
每一台服务器都存储着一个数字作为当前任期的编号,这个数字单调递增。 当节点之间进行通信时,会互相交换当前任期号,若一个节点的当前任期号比其它节点的小,则会更新为较大的任期号。 如果一个Candidate或者Leader意识到它的任期号过时了,就会立刻转换为Follower状态。 当一个节点收到过时任期号的请求,就会直接拒绝这次请求。
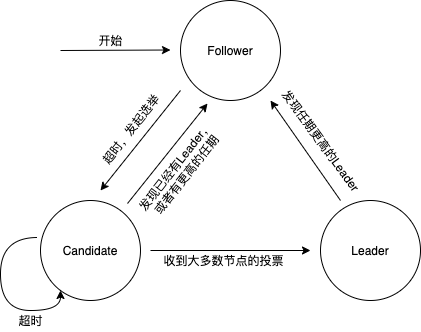
图2.Raft共识流程
总结
Paxos和Raft都是 故障容错(Crash Fault Tolerance) 共识,是非拜占庭问题的容错技术。非拜占庭是指分布式的系统中存在故障(crash fault),但不存在恶意(corrupt)节点的场景(即可能消息丢失或重复,但无错误消息)下的共识达成问题,是分布式共识领域最为常见的问题。相比较于Paxos,Raft更为简洁,同时可以保证同等的容错能力和性能。
—— Part3 概率性共识算法 ——
PoW
工作量证明(Proof of Work,PoW) 最早在1993年由Cynthia Dwork与Moni Naor在学术论文[3]中提及,并于同年由Markus Jakobsson与Ari Juels正式提出了“工作量证明”这个概念[4]。起初,PoW主要用于防止垃圾邮件的产生 。2008年,PoW作为共识算法应用在比特币系统中。PoW有以下3个基本属性:
1)数学难题:PoW共识算法设计了一个 数学难题(Mathematical Puzzle) ,要求节点在生成新区块之前,需要消耗一定的计算资源才能获得难题的解,从而将区块广播到网络,并且其他节点可以轻易验证这个解的有效性。
2)哈希算法: 哈希算法(Hash Algorithm) 是一种能够把任意长度的输入变换成固定长度的输出的算法,可被记为y = hash(x),不同的输入x得到的输出y各不相同。除此之外,在已知x时可以快速计算得到y,但是在已知y的情况下,通常只能通过穷举法才能逆推出x。由于哈希算法具有正向快速、逆向困难的特性,常使用哈希算法来设计PoW的数学难题。
3)生成区块:在一轮区块生成中,系统通过对输出值设定条件来调整数学问题的难度值,节点在成功解出问题并通过验证上链后,将会获得相应的奖励。
在生成新的区块之前,PoW会预设目标值,要求出块节点计算出的哈希值小于该目标值,以此来表示PoW的难度。为了生成区块并获得奖励,出块节点首先收集一组交易打包成一个区块,并开始尝试解决数学问题进行出块。
在此期间,出块节点需要生成随机数,同当前区块数据与前一个区块的哈希进行多轮哈希运算,计算当前区块的哈希值:
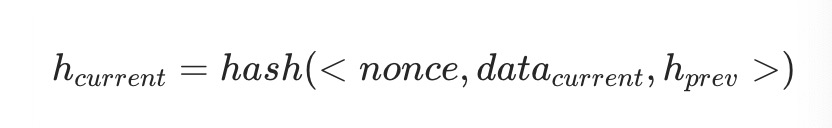
直到当前区块哈希满足条件:
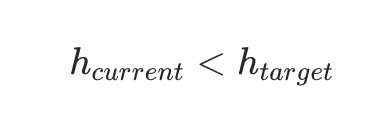
此时的nonce即为本次数学问题的答案,出块节点将当前区块的哈希、nonce值、前一个区块的哈希作为区块头部数据加入当前区块,如图3所示。然后将该区块广播到区块链网络中,等待验证通过后,出块节点就可以取到相应的奖励。
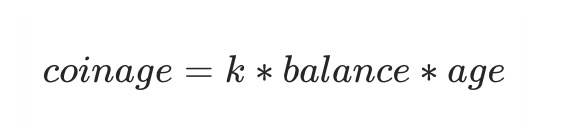
图3.PoW区块结构表示
PoS
前面提到的工作量证明共识算法,就是通过算力来争夺“领导者”的资格,但是工作量证明过程中的大量资源浪费,导致其很难被更大规模的应用接受。对此,有人开始尝试直接使用“股权(Stake)”作为标准进行“领导者”资格的竞选,并随之产生了 权益证明(Proof of Stake,Po S) 共识算法。
PoS的思想来源于社会: 一个人拥有的股份量越多,其获得的股息和分红就会越高 。如果区块链系统也采用这种方法进行维护,不需要过多的资源消耗,也能够使得区块链资产有自然的通胀。节点通过投入一定量的通证参与共识,根据通证持有情况获得打包新区块的权利并获得奖励。目前,以太坊也有转向PoS的以太坊2.0计划。
为了描述通证持有情况,PoS共识算法引入了“币龄”的概念。 币龄(Coin-age) 表示节点持有部分通证的时长,当节点将通证作为“股份”投入后,这部分通证就开始积累币龄,币龄的计算方式如下:
在使用了这部分通证后,无论是用来进行区块生成或者简单的交易,这部分通证对应的币龄将被销毁。在最初的PoS共识算法中,币龄是进行评判的重要标准,节点在区块生成时所使用的币龄越高就越容易产生区块,这可以在一定程度上制约短期投机行为。
PoS共识算法在进行区块生成时,将同时考虑币龄与哈希运算难度,使得节点只需要消耗很少的计算资源就可以完成区块生成。
DPoS
委托权益证明(Delegated Proof of Stake,DPoS) 共识算法[5]中,选举人通过选举产生代表,由代表进行直接的区块产生,选举人通过选举代表人间接行使竞争出块的权利。委托权益证明共识算法,实际上就是通过一系列选拔规则对候选人进行制约,并制定一套投票规则。普通参与者通过投票的方式从候选者中选拔出委托人,并由委托人进行出块,不满足要求的委托人将会被取消权限,并重新选举产生新的委托人。
DPoS保留了一定的中心化特性,因此能够保证高效率的交易吞吐,速率可以比肩常见的中心化机构,例如Visa、Mastercard等。 在该算法中,去中心化的特性主要体现在对于生成区块的权利可控。 即股东通过投票,选择自己信任的代表节点,并由代表节点进行区块链数据的维护。
—— Part4 总结 ——
上述提到的共识算法大多用于 公链 场景,比如比特币,以太坊等,由于公链场景下节点规模庞大,因此较难采用确定性的分布式一致性算法。PoW通过工作量证明的方式来达到较高的安全性以及去中心化程度,相较于PoW,PoS牺牲了一定的安全性来降低能源消耗,而DPoS以更为激进的方式,选举出较少节点来提升共识效率。
在企业级场景下,节点数量不会非常多,但是对于交易吞吐量以及最终确定性要求较高,因此常用联盟链方式来进行建设,从而满足企业级需求。在实际应用场景中,由于拜占庭容错问题,常会使用PBFT及其变体拜占庭容错类共识算法。 对「共识专栏」感兴趣的小伙伴,添加小助手:18458407117加入技术交流群,直面大咖一对一问答~
作者简介
袁超
趣链科技基础平台部共识算法研究小组
参考文献
[1] Lamport L. Paxos made simple[J]. ACM Sigact News, 2001, 32(4): 18-25.
[2] Chandra T D, Griesemer R, Redstone J. Paxos made live: an engineering perspective[C]//Proceedings of the twenty-sixth annual ACM symposium on Principles of distributed computing. 2007: 398-407.
[3] Dwork C, Naor M. Pricing via processing or combatting junk mail[C]//Annual International Cryptology Conference. Springer, Berlin, Heidelberg, 1992: 139-147.
[4] Jakobsson M, Juels A. Proofs of work and bread pudding protocols[M]//Secure Information Networks. Springer, Boston, MA, 1999: 258-272.
[5] Delegated Proof of Stake https://github.com/dacplayproject/cpp-play/wiki/Delegated-Proof-of-Stake


