
科普:IPFS介绍



01 IPFS 前世今生
从今天开始我们聊一聊最近一直比较热门的 IPFS, 又叫星际文件系统(InterPlanetary File System), 通过这篇文章你会对 IPFS 的定义和整体架构有个初步的完整的认识。
IPFS 它是什么?
关于 IPFS 的理解,网上众说纷纭,很多人说它是区块链项目,也有人说它是分布式文件系统,还有人说它是矿机…
这里我们先抛开那些概念,首先我们看看IPFS官网(https://ipfs.io)对它的描述:
A peer-to-peer hypermedia protocol, to make the web faster, safer, and more open.
翻译过来是:一个点对点的超媒体协议,使得互联网更加快速,更加安全,更加开放.
提取一下句子的主谓宾, 你就能得到清晰,简明的定义: IPFS 是一个协议
这样理解起来很简单,但是有点抽象,根据信息论,要想消除一个事物的不确定性,减少信息熵,唯一的目的就是引入更多的信息,所以我们把定语还原:
IPFS 是一个 点对点 的 超媒体 协议。
IPFS 它要干什么?
这个我们还是从 IPFS 官网寻找答案:
IPFS aims to replace HTTP and build a better web for all of us.
这样看来 IPFS 协议诞生的目的是为了干掉 HTTP 协议,HTTP 协议出现到今天已经过去了半个多世纪,确实遇到一些瓶颈,并且 很少有一些设计能够增强整个 HTTP 网络或者为它带来新的功能。IPFS 的目标是就是取代 HTTP,重新建立一个完全去中心化,没有防火墙,没有政府监管,没有监控的 新的互联网世界。
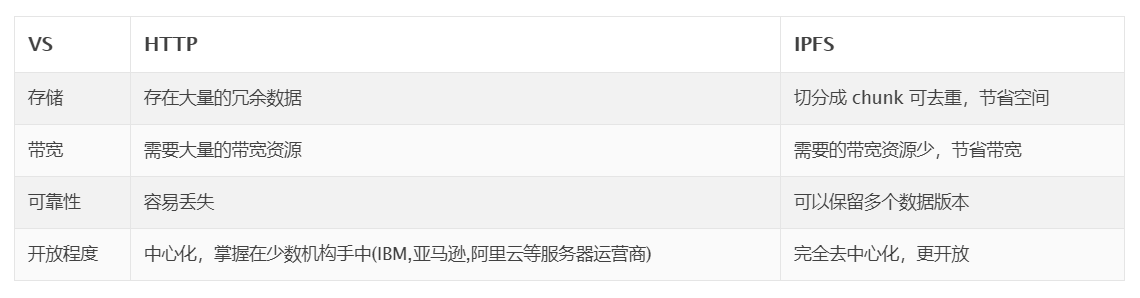
IPFS VS HTTP
首先Http 是一种客户端-服务器的中心化访问模式,IPFS 是完全去中心化. http 是基于地址(主机ip)定位资源的,IPFS 是通过内容地址(Hash)定位资源 (具体的资源访问方式我们会在后面文章专门阐述)。
存储和访问
HTTP 是整文件存储,而 IPFS 是将文件切分成多个 chunk(文件碎片) 分散存储到多个节点,然后通过文件校验机制获取完整文件,这样使得文件的存储和访问更加高效 尤其是对于大文件来说,IPFS 的优势更加明显. 再者,在HTTP的文件系统中,存在大量的重复文件,而 IPFS 通过将文件切片之后,同一个切片只会保存一份, 大大提高文件碎片的重用性,节省存储空间。
传输
IPFS 传输高效,节约带宽资源,IPFS地址不是指的位置,而是直接指向资源,并确保这些数据都是来自最近的资源。 IPFS也会自动选择离你距离最近,带宽最流畅,存储速度最快,最可靠的节点来帮你存储数据,虽然你依然可以使用 HTTP + CDN 来使得服务器更靠近你, 但即使这样,可能最近的服务器还是离你有几百公里远,而且 CDN 的使用成本过高,只有少数大的互联网公司才用的起。
可靠性和持久性
HTTP 的可靠性就不用说了,你每天打开的那些 404 页面已经足够说明问题了。至于持久性,研究表明,现在一个网页的平均寿命是100天。人们每天都在删除历史数据。 IPFS 将会采用和Git类似的机制来记录文件的修改,保留多个数据版本,而不是每次修改后拷贝复制整个文件,并使用梅克尔树(Merkle DAG)来验证文件的完整性。 随着IPFS的缓存系统到位,默认情况下,很多可定期查看的内容完全可以脱机使用。
抵御DDoS攻击
HTTP 服务几乎是没有办法抵御攻击的,必须依赖硬件防火墙这些网络设备。因此一旦有人发起了 DDoS 攻击,将会大大降低 HTTP 服务的可用性。而 IPFS 是天然抗 DDoS 攻击的,因为发动 DDoS 攻击的前提是你必须先知道文件存储在那台服务器上,而 IPFS 的文件是分散存储到很多个节点上,这样就使得你无法定位你要攻击的 节点。
下面用个简单的表格来展示 IPFS 和 HTTP 的现状对比
IPFS 整体架构
作为一个分布式的文件系统,IPFS 提供了一个支持部署和写入的平台,同时能够支持大文件的分发和版本管理;为了达到上述的目的, IPFS 协议被分成如下的几个子协议:(本次只是对各个协议做个简单的介绍,后期我专门对每个子协议做详细的介绍)

总结
本结对 IPFS 做了一整体的介绍,旨在让大家对 IPFS 有个整体的印象,它是一个点对点的超媒体协议,以及大概讲述了它是如何解决 HTTP 当前的一些痛点的。
02 IPFS系列02-IPFS 与 web3.0
IPFS 将对互联网协议进行一次重塑,互联网将进入 web3.0 时代。
web3.0 的特点
- web3.0 应该是一个分布式的,去中心化的可信网络,它是一个真正的公共载体
- web3.0 时代整个互联网将变成一个巨大公共数据库
- web1.0 是机器与机器互联,web2.0 是人与人互联,web3.0 应该是万物互联
http 的缺陷和 ipfs 的目标
http 是 web1.0 以及 web2.0 的基础协议,互联网的本意是要开放,互联,去中心化,它基于 http 协议, 但是 http 一个脆弱的、高度集中的、低效的、过度依赖于骨干网的协议。
http 非常脆弱
我们首先来看一张图片:
据说这是史上第一台 http 服务器,上面贴的纸条是不是特别眼熟,”这台机器是服务器,不要关机!”。这将 http 服务器的脆弱性完美的呈现出来。
为什么不能关机,因为这台服务器关闭之后整个服务就瘫痪了。
你也许经常看到这样的结果:


发生这种情况的原因很简单:中心化管理的 Web 服务器不可避免地会关闭。域名更改所有权,或者运行它的公司破产。或者计算机崩溃,没有备份来恢复内容。
前段时间我清理了自己的网页收藏夹,发现居然有 30% 的收藏页面现在居然打不开了。
http 鼓励中心化
不管我们是否承认,现在几乎我们使用的 90% 的互联网服务都来自不到 1% 网站提供,甚至数十亿的用户不得不依赖少数几个公司提供的服务。http 使得 web 越来越中心化。
http 对主干网的过度依赖,使得对互联网的监听和审查变得非常低,只需要拦截几个主干网就可以轻松实现。 而且 Internet 骨干网并不健全,其很容易被攻击,同时一些重要的光纤线路被切断时服务很容易遭受影响。
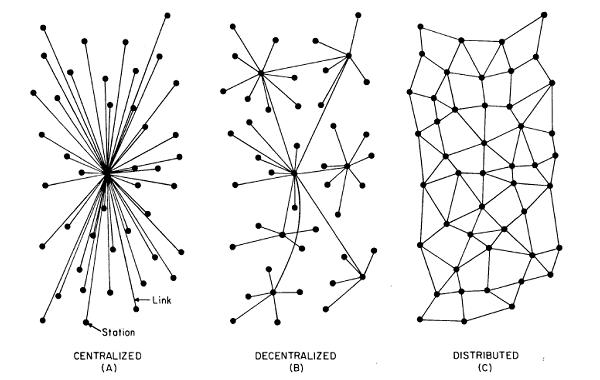
随着互联网的影响力越来越大,政府和企业都开始撬开 http 的缺陷,利用它们来监视用户,并阻止用户访问任何对他们构成威胁的内容。
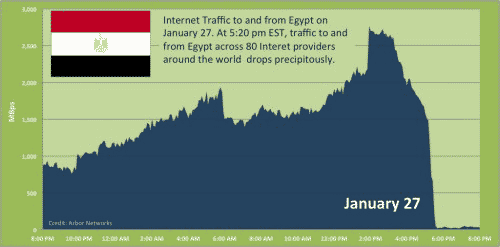
2011年1月28日,埃及切断了全国的互联网。
从下图可以看到,1月27日午夜,埃及的国际数据流量一下子跌到了接近零。
骨干网上,埃及与外界连通的3500个路由器,都没有回应。对于埃及民众来说,互联网已经彻底无法使用了,任何网站都打不开; 对于国外访问者来说,不仅打不开埃及网站,甚至连IP地址也找不到,好像它们根本不存在一样。
国际路由表(global routing table)上,凡是与埃及有关的表项都失效了。埃及政府成功地使本国在一夜之间脱离了互联网,”把自己从世界地图上抹去了”。
中心化带来的另一风险就是,使我们的通信面临被 DDoS 攻击中断的风险。
http 效率低下,成本高昂
首先我们来说说效率问题,假设你正在腾讯视频看《复仇者联盟4》的 4K 视频,你的坐标在北京,而腾讯的服务器却在深圳(先不考虑 CDN), 这样你不得不等待视频从深圳传输到北京,如果你的网速足够快,而且此时只有一个人在看,你可能感觉不到卡顿的情况。但是如果此时北京还有 1000 个用户跟你一样也在 看《复仇者联盟4》,这个时候相当于腾讯的服务器需要从深圳同时传输 1000 视频到北京,这个时候你的观影体验就会极速下降,变成”缓冲五分钟,观影三分钟”。
于此同时,腾讯将要向 ISP 服务商付出高昂的成本来分发这些视频数据,假设《复仇者联盟4》这部电影的 4K 视频是 2GB,那么 1000 用户总共需要分发接近 2TB 的数据。 假设按照每1GB 0.1RMB 算,总共需要支付 200 RMB,好像也不多,但是事实上像《复仇者联盟4》这种热门电影的观看次数一般都过亿的, 这样算来腾讯需要支付 2000 万来完成数据分发。
如果我们可以将 ISP 网络上的每台计算机变成流式 CDN,而不是总是从数据中心提供这些内容,那该怎么办? 像一些热门视频甚至可以从ISP的网络中完全下载,不需要通过互联网骨干网进行大量跳跃。这就是 ipfs 要解决的问题。
IPFS 如何实现目标
我们已经讨论了http 的缺陷(以及超中心化的问题),现在让我们谈谈IPFS如何以及如何帮助改进网络。
首先 ipfs 从根本上改变了我们搜索互联网文件的方式,它是一种基于内容寻址、版本化、点对点超媒体的分布式存储、传输协议。
我们通过 http 去访问一个文件时,首先需要通过 IP 地址定位文件所在的服务器,然后还需要知道文件的路径,才能正确的访问到一个文件, 这种模式叫做IP和路径寻址。
而在 ipfs 网络里,当文件被添加到 ipfs 节点时候,ipfs 会根据文件的内容生成一个加密哈希值(以 Qm 开头),你只要知道这个哈希值, 就可以根据哈希值定位道这个文件,这种模式叫做内容寻址。密码学保证该哈希值始终只表示该文件的内容。哪怕只在文件中修改一个比特的数据,哈希都会完全不同。
IPFS 工作原理
- 使网站脱机变得很困难,如果有人攻击维基百科的网络服务器或维基百科的工程师犯了一个大错误,导致他们的服务器着火,你仍然可以从其他节点获得相同的页面。
- IPFS 节点的上面的文件只能添加,无法删除,确保不会出现 http 404 这样的错误,并且如果你修改一个文件重新添加,IPFS 会重新生成跟原文件不同的哈希值, 篡改后的文件在 IPFS 网络里面是新的文件,你通过原来的哈希访问的一定是你添加的的那个文件,而不是篡改后的文件。
- 使主管部门审查内容变得更加困难,因为 IPFS 上的文件可能来自很多地方,并且因为其中一些地方可能就在附近, 由于它不需要主干网,所以政府或者组织想要拦截数据进行审查几乎做不到。像土耳其阻止维基百科和西班牙阻止访问加泰罗尼亚独立网站这种事情将不会再发生。
- 理论上只要网络足够大,IPFS 分布式网络将很快成为世界上最快、最可用、以及最大的数据存储网络。任何节点宕机都不会影响 IPFS 网络对外提供服务, 没有人有能力关闭所有的节点,所以数据永远不会丢失。
- 由于 IPFS 网络是基于内容寻址的,所以它天然就抗 DDoS 攻击,因为你不知道数据存储在哪,无法找到攻击目标。
- IPFS 采用分片存储,而相同的分片哈希值是相同的,因此 IPFS 网络中不会存储两个相同的分片,既节省了存储空间,又节省了带宽。
IPNS
IPFS 哈希代表不可变的数据,这意味着它们是不能被更改的,否则会导致哈希值的变更。这是一件好事,因为它鼓励数据的持久性, 但如果一个网站内容每天都有更新的话,意味着这个网站的地址每天都在改变,作为用户来说,这是无法接受的。
IPFS 提供了一个特殊的解决方案 IPNS (Inter-Planetary Naming System),它允许用户使用公钥作为代表网站根目录的哈希的引用,然后使用私钥对引用进行签名。 由于公钥是保持不变的,所以用户不需要每次更改地址,每次站点更新只需要重新生成新的引用然后签名就好了。
可以简单理解为通过节点 ID 对项目根目录的 IPFS 哈希进行绑定,以后我们访问网站时直接通过节点 ID 访问就好了。
虽然解决了站点更新的问题,但是 IPFS 的哈希值毫无规律,很难记忆,可读性极低。因此 IPNS 允许你使用现有的 DNS 来提供人类可读的网站地址, 它通过允许您将哈希值插入名称服务器上的 TXT 记录来实现此目的:
接下来我们就可以通过 http://ipfs.io/ipns/www.r9it.com/ 来访问站点了。
IPFS 网关,新旧网络之间的桥梁

- 通过 IPFS 客户端命令行工具
- 通过 IPFS 的浏览器插件,IPFS 伴侣
- 通过 IPFS 节点内置的 http 网关(http://127.0.0.1:8080)
前两个中方式访问起来比较麻烦,但是 IPFS 网关允许用户实现 http 和 IPFS 的无缝对接,用户可以开始慢慢的把他们的服务迁移到 IPFS 网络了。
IPFS 与 web3.0
- 首先,IPFS 结合区块链可以实现一个分布式的,可信的网络。
- 其次,IPFS 可以把整个互联网改造成一个巨大的存储系统。
- 再次,IPFS 提出的点对点超媒体协议,为万物互联提供了底层协议解决方案。


