
区块链中的共识机制分析与对比



作者:郑翊
目录
- 什么是共识机制
- 拜占庭将军问题
-
CAP原理
- 定义
- 应用
-
拜占庭问题的常规解法
- 口头协议
- 书面协议
- PBFT
-
比特币中对于拜占庭问题的解法
-
PoW
- Bitcoin
- Ethereum
-
PoS
- Peercoin PoS v1
- Blackcoin PoS v2
- Blackcoin & Qtum PoS v3
- Ethereum Casper
-
Delegated Methods
- EOS DPOS
- NEO DBFT
-
PoW
-
非拜占庭问题下的解法
- Paxos
- Raft
- 总结
- 参考资料
什么是共识机制
区块链从本质上而言是一种分布式账本技术。传统的账本,通常会以数据库的形式,集中存储在银行或公司的服务器节点上。而在区块链的网络中,每个节点都会保有一份完整的账本,且所有节点的账本内容完全一致。每个节点都可以根据自己本地的账本去查找交易,也可以往账本中添加交易。
这样就带来了一个问题,如果所有节点同时一起写入账本数据,那么肯定数据会不一致。因此需要一种机制来保证区块链中的每一区块只能由一个节点来负责写入,并且让所有其他节点一致认同这次写入。如何选出写入账本数据的节点,这就是共识机制。
拜占庭将军问题
拜占庭将军问题[1][2](Byzantine Generals Problem)是对上述场景的一种建模。拜占庭将军问题是一个共识问题: 首先由Leslie Lamport与另外两人在1982年提出,被称为The Byzantine Generals Problem或者Byzantine Failure。核心描述是军中可能有叛徒,却要保证进攻一致,由此引申到计算领域,发展成了一种容错理论,即拜占庭容错(BFT,Byzantine Fault Tolerance)。
拜占庭将军问题可以描述如下:
拜占庭帝国想要进攻一个强大的敌人,为此派出了10支军队去包围这个敌人。这个敌人虽不比拜占庭帝国,但也足以抵御5支常规拜占庭军队的同时袭击。基于一些原因,这10支军队不能集合在一起单点突破,必须在分开的包围状态下同时攻击。他们任一支军队单独进攻都毫无胜算,除非有至少6支军队同时袭击才能攻下敌国。他们分散在敌国的四周,依靠通信兵相互通信来协商进攻意向及进攻时间。困扰这些将军的问题是,他们不确定他们中是否有叛徒,叛徒可能擅自变更进攻意向或者进攻时间。在这种状态下,拜占庭将军们能否找到一种分布式的协议来让他们能够远程协商,从而赢取战斗?这就是著名的拜占庭将军问题。
解决问题的难点在于,将军中可能出现叛徒,叛徒可以通过选择性地发送消息,从而达到混淆进攻决策的目的。假设有9位将军投票,其中1名叛徒。8名忠诚的将军中出现了4人投进攻,4人投撤离的情况。这时候叛徒可能故意给4名投进攻的将领送信表示投票进攻,而给4名投撤离的将领送信表示投撤离。这样一来在4名投进攻的将领看来,投票结果是5人投进攻,从而发起进攻;而在4名投撤离的将军看来则是5人投撤离。这样各支军队的一致协同就遭到了破坏。
拜占庭将军问题对应到分布式系统中,可以表述为分布式的节点间需要对某一个message达成共识(只要过半数节点认同这个message即可)。节点之间可以交换信息,但是由于恶意节点的存在,恶意节点会发布错误的消息,或是给不同的节点发送不同的消息。在这样的场景下,怎样设计一种机制去让节点能够达成共识的问题。
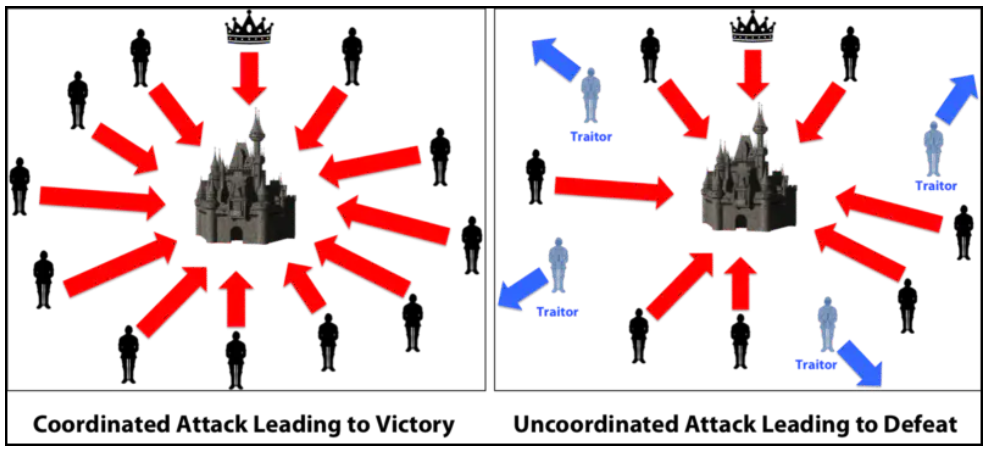
拜占庭问题的传统解法
口头协议
首先明确口头协议的定义。我们将满足以下三个条件的方式称为口头协议:
- 每个被发送的消息都能够被正确的投递
- 信息接收者知道是谁发送的消息
- 能够知道缺少的消息
Lamport论证得出结论:将军之间采用口头协议进行通信,若叛徒数少于1/3,则拜占庭将军问题可解。也就是说, 若叛徒数为m,当将军总数n至少为3m+1时,问题可解 。本文中不再详细介绍通信机制和论证过程,有兴趣的读者可以查阅文章[1]中“口头协议”一节和[2]中的“Early solutions”下的第一种。
书面协议
在口头协议上加上一个条件,使之成为书面协议
- 发送者对消息加上签名,签名不可伪造,一旦被篡改即可发现,而叛徒的签名可被其他叛徒伪造;
- 任何人都可以验证签名的可靠性。
可以论证,在将军之间使用书面协议通信的基础上,不管将军总数n和叛徒数量m,忠诚的将军总能达到一致。书面协议的本质就是引入了签名系统,这使得所有消息都可以追溯到底有谁认同了它。这一优势,大大节省了成本,他化解了口头协议中1/3要求,只要采用了书面协议,忠诚的将军就可以达到一致。即恶意的节点不超过半数,分布式系统就能达成共识。对推导细节感兴趣的读者可以同样参照[1][2]。
PBFT
实用拜占庭容错协议(PBFT,Practical Byzantine Fault Tolerance)是Miguel Castro (卡斯特罗)和Barbara Liskov(利斯科夫)在1999年提出来的,解决了原始拜占庭容错算法(即上文中的口头协议)效率不高的问题,将算法复杂度由指数级降低到多项式级,使得拜占庭容错算法在实际系统应用中变得可行。
PBFT算法的结论是n>=3f+1 n是系统中的总节点数,f是允许出现故障的节点数。换句话说,如果这个系统允许出现f个故障,那么这个系统必须包括n个节点,才能解决故障。这和上文口头协议的结论一样,或者这么说,PBFT是优化了口头协议机制的效率,但是结论并未改变。
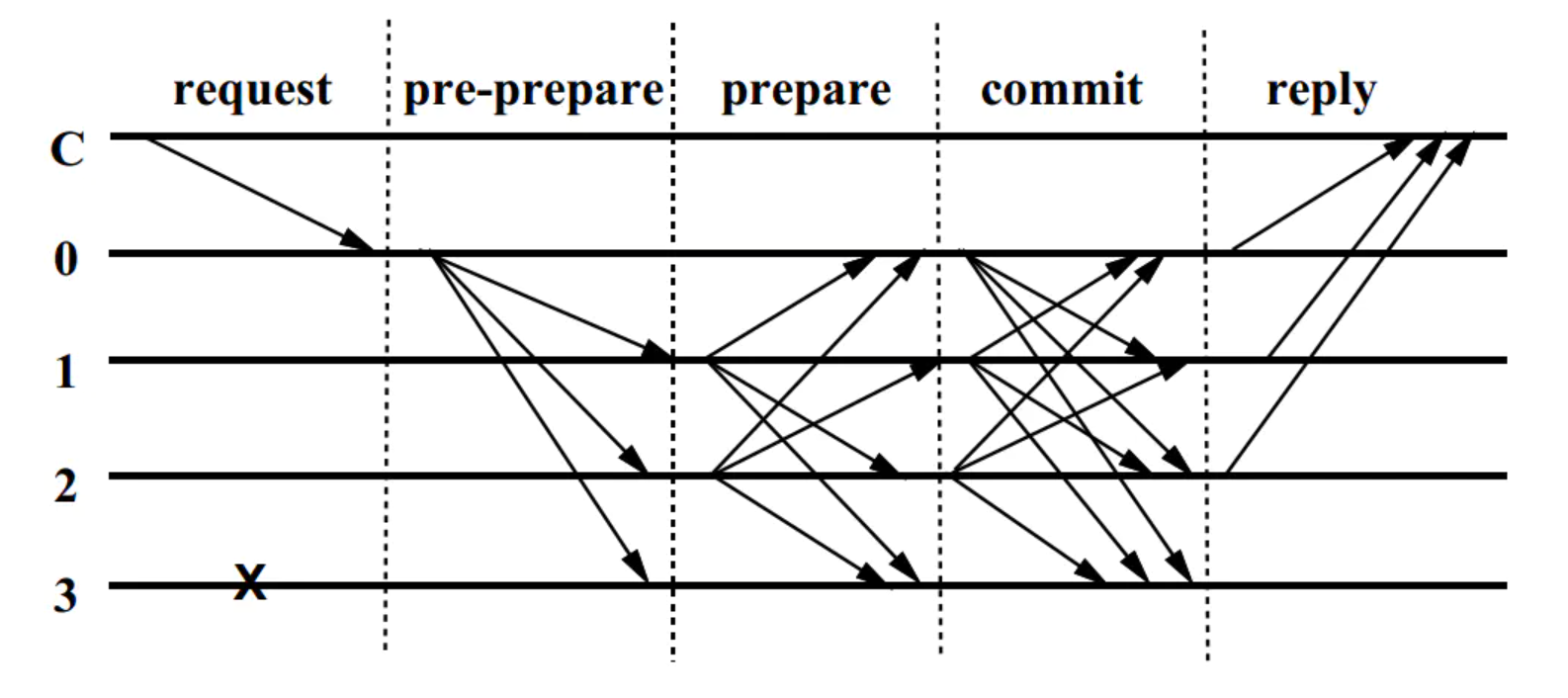
PBFT算法的步骤,详见[1][3]
- 取一个副本作为主节点(图中0),其他的副本作为备份;
- 用户(图中C)向主节点发送消息请求;
- 主节点通过广播将请求发送给其他节点(图中1、2、3);
- 所有节点执行请求并将结果发回用户端;
- 用户端需要等待f+1个不同副本节点发回相同的结果,即可作为整个操作的最终结果。
CAP原理
为了便于理解比特币中对于拜占庭问题的解法(PoW、PoS等),先看一下著名的CAP原理[4],对于共识算法的设计有指导意义。CAP 原理最早由 Eric Brewer 在 2000 年,ACM 组织的一个研讨会上提出猜想,后来 Lynch 等人进行了证明。该原理被认为是分布式系统领域的重要原理。
定义
分布式计算系统不可能同时确保一致性(Consistency)、可用性(Availability)和分区容忍性(Partition),设计中往往需要弱化对某个特性的保证。
- 数据一致性(Consistency):如果系统对一个写操作返回成功,那么之后的读请求都必须读到这个新数据;如果返回失败,那么所有读操作都不能读到这个数据,对调用者而言数据具有强一致性(strong consistency) (又叫原子性 atomic、线性一致性 linearizable consistency)
- 服务可用性(Availability):所有读写请求在一定时间内得到响应,可终止、不会一直等待
- 分区容错性(Partition-tolerance):在网络分区的情况下,被分隔的节点仍能正常对外服务
在某时刻如果满足AP,分隔的节点同时对外服务但不能相互通信,将导致状态不一致,即不能满足C;如果满足CP,网络分区的情况下为达成C,请求只能一直等待,即不满足A;如果要满足CA,在一定时间内要达到节点状态一致,要求不能出现网络分区,则不能满足P。C、A、P三者最多只能满足其中两个。
分区容错性
这里重点讲一下对分区容错性的理解,便于大家理解CAP。Partition字面意思是网络分区,即因网络因素将系统分隔为多个单独的部分,有人可能会说,网络分区的情况发生概率非常小啊,是不是不用考虑P,保证CA就好。要理解P,我们看回CAP证明中P的定义:
In order to model partition tolerance, the network will be allowed to lose arbitrarily many messages sent from one node to another.
网络分区的情况符合该定义,网络丢包的情况也符合以上定义,另外节点宕机,其他节点发往宕机节点的包也将丢失,这种情况同样符合定义。现实情况下我们面对的是一个不可靠的网络、有一定概率宕机的设备,这两个因素都会导致Partition,因而分布式系统实现中P是一个必须项,而不是可选项。
弱化一致性
对结果一致性不敏感的应用,可以允许在新版本上线后过一段时间才更新成功,期间不保证一致性。
例如网站的CSS、JS等,通常都设置了一定的缓存时间。超过缓存时间才会重新去服务器获取最新的版本。
弱化可用性
对结果一致性很敏感的应用,特别是交易相关的应用场景,通常会用到锁、事务等概念。
例如银行取款机,当系统故障时候会拒绝服务。Paxos、Raft 等算法,主要处理这种情况。
弱化分区容忍性
现实中,网络分区出现概率减小,但较难避免。某些关系型数据库、ZooKeeper 即为此设计。一旦有部分节点网络通信出现故障,则暂停这部分节点,不再提供对外服务。
比特币中对于拜占庭问题的解法
拜占庭问题之所以难解,在于任何时候系统中都可能存在多个提案(因为提案成本很低),并且要完成最终的一致性确认过程十分困难,容易受干扰。但是一旦确认,即为最终确认。
比特币的区块链网络在设计时提出了创新的 PoW(Proof of Work) 算法思路。一个是限制一段时间内整个网络中出现提案的个数(增加提案成本),另外一个是 放宽对一致性确认的需求 ,约定好大家都确认并沿着已知最长的链进行拓宽。系统的最终确认是概率意义上的存在。这样,即便有人试图恶意破坏,也会付出很大的经济代价(付出超过系统一半的算力)。
或者通俗来说,比特币的PoW共识弱化了拜占庭问题中对于一致性的要求,在同一时刻访问不同比特币的节点,所得到的共识并不一致,且一致性还会随着时间改变(分叉的情况)。但是可用性和分支容错性都得到了提升。
后来的各种 PoX 系列算法,也都是沿着这个思路进行改进,采用经济上的惩罚来制约破坏者。
PoW
Bitcoin
Bitcoin的共识协议,可以参照Mastering Bitcoin[5]中有详细的描述。其步骤如下:
- 本地维持所有未被确认的交易,称之为交易池,每新接收到一笔交易就加入到交易池中
- 本地维持整个区块链,每新接收到一个block,则加入到区块链中,并根据最长链原则确定主链
- 当新接收到的block加入到区块链的时候,开始挖矿
- 构建一个空的block,选取交易池中费率最高的交易填充block,费率的定义为 交易费/交易大小
- 根据主链,填充block header中的previous block hash字段
- 根据block中所有交易的交易费和挖矿奖励,构建coin base交易。挖矿奖励大约 每四年(或准确说是每210,000个块)减少一半,开始时为2009年1月每个区块奖励50个比特币
- 修改block header中的nonce, timestamp, merkle root(通过修改coinbase data),让hash(block header) < difficulty,其中difficulty是根据近期block的产出时间来计算的,保证每个block产出的时间大致是10分钟左右
- 由于满足hash要求的block head只能通过大量遍历获得,所以挖矿的过程需要消耗大量的算力,直到得到合适的字段取值为止
- 发布得到的block,其他节点验证通过后加入区块链中
2010 年左右,挖矿还是一个很有前途的行业。但是现在,建议还是不要考虑了,因为从概率上说,由于当前参与挖矿的计算力实在过于庞大(已经超出了大部分的超算中心),获得比特币的收益已经眼看要 cover 不住电费了。
从普通的 CPU(2009 年)、到后来的 GPU(2010 年) 和 FPGA(2011 年末)、到后来的 ASIC 矿机(2013 年初,目前单片算力已达每秒数百亿次 Hash 计算)、再到现在众多矿机联合组成矿池。短短数年间,比特币矿机的技术走完了过去几十年的集成电路技术进化历程,并且还颇有创新之处。
Ethereum
由于ASIC矿机被大量运用在比特币的挖矿过程中,所以如果出现其他基于hash运算达到共识的区块链,则很容易受到原本服务于比特币的ASIC矿机攻击。因此Ethereum在设计其PoW共识算法的时候,就意识到应该让算法在普通的个人电脑上运行更有优势,从而避免被ASIC进行攻击。
Ethash设计时就明确两大目标:
- 抵御矿机性能(ASIC-resistance),团队希望CPU也能参与挖矿获得收益。
- 轻客户端可快速验证(Light client verifiability)。
基于以上两个目标,开发团队最后倒腾出来的Ethash挖矿时基本与CPU性能无关,却和内存大小和内存带宽成正相关。不过在实现上还是借鉴了SHA3的设计思路,但是使用的”SHA3_256” ,”SHA3_512”与标准实现很不同。
Ethash基本流程是这样的[6]:对于每一个块,首先计算一个种子(seed),该种子只和当前块的信息有关;然后根据种子生成一个32M的随机数据集(Cache);紧接着根据Cache生成一个1GB大小的数据集合(DAG),DAG可以理解为一个完整的搜索空间,挖矿的过程就是从DAG中随机选择元素(类似于比特币挖矿中查找合适Nonce)再进行哈希运算。可以从Cache快速计算DAG指定位置的元素,进而哈希验证。此外还要求对Cache和DAG进行周期性更新,每1000个块更新一次,并且规定DAG的大小随着时间推移线性增长,从1G开始,每年大约增长7G左右。
PoS
可以看到,PoW会存在两点问题:
- 费电。无论是比特币的共识还是以太坊的Ethash,挖矿的过程中都带来了巨大的电力消耗。网上有报道称,现在每挖一个比特币的成本在6000-8000美元之间;比特币现在每天消耗的电量相当于一个小国家的耗电量。
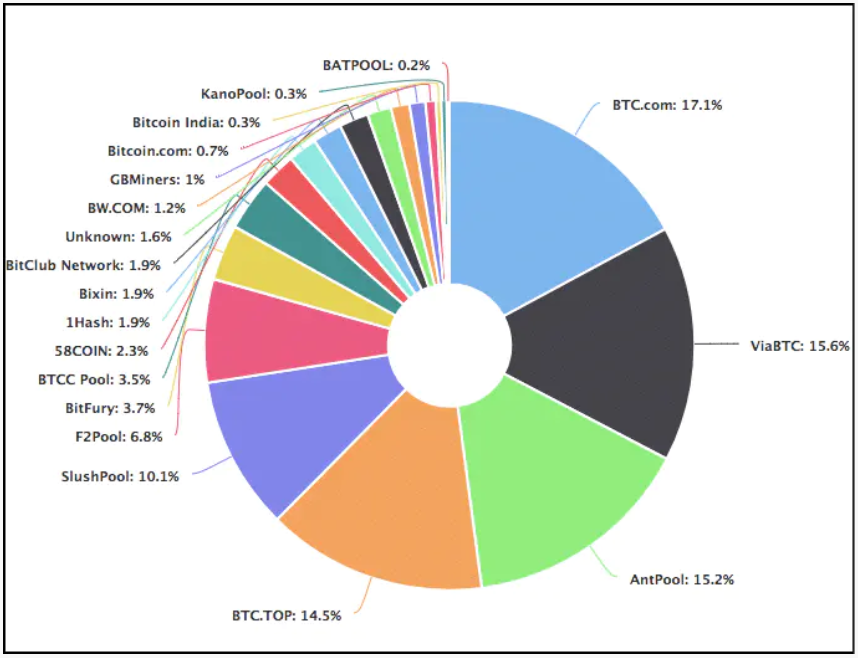
- 矿池的优势。随着算力的不断提升,单个矿机挖出一枚币的概率降到了极低。因此,很多矿机的拥有者联合在了一起形成矿池。矿池中的矿机并行地分担计算量,当挖出新的block获得奖励后,再根据计算量的贡献分享奖励。矿池的出现导致了比特币的中心化。从下图中可以看出,65%的算力集中在了5大矿池的手里。如果这些矿池对比特币网络进行攻击,则网络会面临较大的风险。
因此,业内提出了PoS(Proof of Stake)[7]的思想:
- 把生产block的工作交给拥有更多token的人,拥有的越多,作为block producer的概率越高
- 生产block的过程中得到token奖励,可以理解为持有token带来的利息
- 拥有大量token的人如果攻击网络,则会造成token价格的下降,对这些人是不利的,所以这些block producer攻击网络的意愿较低
- 生产block只需证明自己持有的token即可,不需要消耗多少算力,节约能源
围绕以上PoS的思想,各个区块链系统有不同的PoS实现,以下将依次介绍
Peercoin PoS v1
最初的一版PoS由Peercoin设计实现[8]。其中,用户要产出block必须满足以下条件
hash(stake_modifier, current_time, UTXO) < coin(UTXO) * age(UTXO) * difficulty复制代码具体解释如下
- 用户在每一秒时间(current_time),遍历自己所有的UTXO,代入上述公式中,看是否能满足不等式条件;如果满足,就把相应的UTXO记录在block中,并发布block(见4)
- stake_modifier是对前一个block中部分字段hash后的值,加入这一项是为了防止用户提前预知自己何时有权挖矿
- difficulty会根据近期的block产出时间动态调整,保证block产出时间间隔稳定
- 由于每秒只需要完成和自己UTXO数量相等的hash计算,所以需要的算力较低
- 从不等式可以看出,持有的UTXO越多、UTXO中token数额越大(coin(UTXO))、UTXO持有时间越长(age(UTXO),或称之为币龄),不等式越容易成立,越容易进行挖矿
- 生成block的奖励设置为了coin(UTXO) * age(UTXO),即UTXO数额越大持有时间越长,奖励越高
- 为了将符合条件的UTXO记录进block,并且兼容原本的PoW模式,Peercoin设计了coinstake的逻辑
- 保留原本第一个transaction为coinbase,但要求输入数量必须等于1,且输入的prevout字段必须置空值,输出数量必须大于等于1
- 令第二个transaction为coinstake,要求输入数量大于等于1,且第一个输入为满足条件的UTXO,输出数量大于等于2,且第一个输出必须置空值,第二个输出为block奖励

该版本的PoS面临着如下的问题
- 因为构造新的block没有算力成本,所以当区块链出现fork的时候,用户有可能会倾向于同时在多个branch一起挖矿来获得潜在更高的收益,这样制造了大量的分支,破坏了一致性。这个问题多次被以太坊团队提及,并称之为nothing at stake问题[12],以太坊在其PoS方案CASPER中致力于解决该问题,下文Ethereum Casper一节中将详细描述
- 出现了攒币龄的现象,即关闭节点,直到age(UTXO)足够大的时候再启动节点挖矿,从而节省电力,这样引起了在线节点数太少系统脆弱的问题
- 可以攒够足够的币龄后,保证自己有足够的UTXO能够连续生产block,从而发动double-spend攻击
Blackcoin PoS v2
Blackcoin在Peercoin的基础上进行了修改,从而缓解了上述问题,主要改动如下,全部改动参见[9]
- 去掉了不等式公式右边的age(UTXO),从而解决了问题3中攒币龄然后进行double-spend的现象;但是block奖励还是使用了币龄,因此并不能完全解决问题2中节点关闭的现象
- 优化了stake_modifier的计算逻辑,让用户提前预知自己有权挖矿时间的难度更大了
Blackcoin & Qtum PoS v3
Blackcoin又在v2的基础上改进得到了v3[10],然后Qtum对v3又进行了修改并应用[11]。主要改动点描述如下,全部改动请参照[10][11]
- 把block奖励改成固定值,解决了问题2
- 规定500个block之前的UTXO才能参与挖矿,缓解挖矿过于频繁带来的潜在风险
Ethereum Casper
Ethereum在其白皮书中承诺最终将从PoW过渡到PoC,并且其PoC的方案,名叫CASPER[12],正在积极开发中。CASPER一个主要改进点是其将致力于解决nothing at stake问题,主要的方式是惩罚在多个分支上同时进行挖矿的用户,甚至让这些用户失去用于stake的那部分token。其方案描述如下:
- 用户质押自己的一部分token进入智能合约,然后开始挖矿
- 如果成功挖到block并被网络接受,则用户获得奖励
- 如果用户被系统发现试图进行nothing at stake行为,则其质押的token将被销毁
但对于nothing at stake问题,业界一直是有争议的[13]。主要观点就是执行这种攻击的代价太高,而且对攻击者是毫无收益的。这和PoW的前提假设一样,拥有大量矿机的人可以对比特币发动double-spend等攻击,但是这样的攻击对其并无收益,且会损失大量算力,所以这种攻击并没有大量发生。
Delegated Methods
以上的PoW和PoS的挖矿过程,是全网所有节点共同参与的,每一时刻都有成千上万个节点同时去争取产出下一个block,因此会时有发生区块链分叉(fork)的问题。即同一时刻,两个节点同时产出了next block,但由于网络时延的问题,block产出的时候两个节点并不知道有其他节点已经产出了另一个block,因此这两个block都被发布到了网络中。[5]中对分叉的问题有详细的描述,可以进行参考。
正是由于分叉的存在,block的产出时间间隔不能太短。各区块链通过动态调整的挖矿难度,将block时间间隔稳定在自己期望的水平。例如最初比特币的间隔是10分钟,后续的以太坊是15秒左右。如果时间间隔进一步调短(即降低挖矿难度),分叉问题就会大量显现,不利于共识的达成和系统的稳定。
block产出时间过长导致了两个问题:
- 交易确认所需的时间过长。通常来说,一笔交易进入区块链后,都建议经过6个block之后才真正确认交易,因为6个block之后想要再分叉并且追赶主链的难度已经超乎想象了。因此,在区块链上确认交易需要分钟级别的时间。
- TPS (Transactions Per Second) 受到制约。TPS受到了block generation time和max block size的共同制约。其中max block size的存在是为了防止DOS攻击等因素[14],有一定的天花板,因而缩减block generation time至关重要
为了缩短block产出时间,delegated开头命名的系列方法被提了出来。其基本思想就是,选出少量的代表来负责生产block。这样即使缩短block的时间间隔,也不会有严重的分叉发生。甚至可以使用PBFT这种没有分叉的方法来达成代表之间的一致共识。
EOS DPOS
EOS提出的DPOS方案[15],其步骤简述如下
- 持有token的用户可以对候选的block producer进行投票;虽然没有看到对投票过程的详细设计,但是相关文章中提到了一种可选的方法,即用户在生成交易的时候,把自己的投票包含在交易中
- 得票最高的n个用户被选为代表,在下一个周期中负责产出block,目前n=21
- 打乱代表的顺序后,各代表开始依次生产block。每个代表都有自己固定的时间区间,需要在自己的区间中完成block的生产发布。目前这个区间是3秒,即在正常情况下每3秒产出一个block
- 每个代表在生产block的时候,需要找当时唯一的最长链进行生产,不能在其他分支上进行生产
- EOS论证了在这种机制下,只要n>=3f+1(n是系统中的总节点数,f是允许出现的恶意节点数),则共识能够达成
通过上述方法,EOS保证了较短的block生产时间(3秒),且因为给每个生产者设置了固定的时间区间,则block的产出不会因为某个候选节点的延迟而延迟。EOS的文章中详细论述了各种节点异常情况下的共识达成,有兴趣可以参考。
NEO DBFT
NEO的共识机制也是先选代表,和EOS的不同之处在于,代表之间是按照PBFT的方式达成共识的。由于上文中已经描述了PBFT算法,所以这里就不再解释DBFT的原理了,有兴趣的读者可以参照[16]
非拜占庭问题下的解法
以上的算法都是在拜占庭问题建模下的共识算法,以下将介绍“非拜占庭问题”。在拜占庭问题中,我们认为每个节点是可以进行恶意的攻击的,即节点在传递消息的过程中,可以给不同节点传递不同的消息,从而破坏共识。这种场景是符合开放的网络环境的。
而在较为封闭的网络环境中,比如我们常说的私有链,或是公司内部的一些分布式系统中,每个节点是可信的,不会存在恶意的攻击者。节点在传递消息的过程中,只会因为网络不稳定或是节点挂掉出现漏传、重传消息的情形。因此,有一类算法是用于解决在这种场景下的共识问题,因此我们称这种场景建模为非拜占庭问题。
Paxos
早在1990年,Leslie Lamport(即 LaTeX 中的"La",微软研究院科学家,获得2013年图灵奖)向ACM Transactions on Computer Systems (TOCS)提交了关于Paxos算法的论文The Part-Time Parliament。几位审阅人表示,虽然论文没什么特别的用处,但还是有点意思,只是要把Paxos相关的故事背景全部删掉。Leslie Lamport心高气傲,觉得审阅人没有丝毫的幽默感,于是撤回文章不再发表。直到1998年,用户开始支持Paxos,Leslie Lamport重新发表文章,但相比1990年的版本,文章没有太大的修改,所以还是不好理解。于是在2001年,为了通俗性,Leslie Lamport简化文章发表了Paxos Made Simple,这次文中没有一个公式。
但事实如何?大家不妨读一读Paxos Made Simple。Leslie Lamport在文中渐进式地、从零开始推导出了Paxos协议,中间用数学归纳法进行了证明。可能是因为表述顺序的问题,导致这篇文章似乎还是不好理解。所以这里我摘录了一篇对Paxos描述的中文文档[17],供参考。
想要看懂Paxos**识达成的机制较为简单,其基本来说就是一个二次确认的过程。
- 首先由用户向网络中所有节点发出提议n,n是提议的编号
- 节点收到提议n后
- 若编号n比之前接受的提议请求都要大,则承诺将不会接收提议编号比n小的提议,并且带上之前接受的提议中编号小于n的最大的提议{n0, v0},n0是编号,v0是内容(如果之前没接受过提议则返回空的消息)
- 否则不予理会
- 用户得到了多数节点的承诺后
- 如果发现承诺的节点返回的都是空,则向所有节点发送自己本次提议的{n, v},让大家接受
- 否则,从所有节点返回中选择n0最大的v0,作为提议的值,提议编号仍然为n,即向所有节点发送{n, v0}让大家接受
- 节点接收到提议后,如果该提议编号不违反自己做过的承诺,则接受该提议。
Paxos证明了在这种机制下,只要挂掉的节点小于半数,则能实现系统的共识。
Raft
Paxos协议是第一个被证明的一致性算法,但是Paxos的论文非常难懂,导致基于Paxos的工程实践和教学都十分头疼,于是Raft在设计的过程中,就从可理解性出发,使用算法分解和减少状态等手段,目前已经应用非常广泛。可以这么理解,Raft改进了Paxos的机制,便于理解和在实际场景中编程实现。
Raft的详细描述可以参照[18],由于篇幅所限本文就不详细介绍了。
总结
本文的目的是列举目前区块链系统中,已经应用的主流共识机制,并附带介绍了Paxos和Raft这两种非拜占庭问题下的共识算法,便于对所有共识算法有更好的理解。由于所涉及的算法较多,所以本文并未对算法的细节进行特别详细的描述,而是罗列了相关的参考文献,便于读者更加详细地去了解算法细节。
本文的主要贡献是描述了各个算法的设计思路、使用场景,也许可以使读者了解每个算法是怎么想出来的以及怎么使用。另外,本文还对比了算法之间的优缺点,便于读者去了解算法的不同。
还有一些正在测试中或是开发中的共识机制,将在后续文章中进一步阐述。
参考资料
[1] 拜占庭共识机制
[3] 实用拜占庭容错算法PBFT
[4] 分布式系统理论基础 - CAP
[6] Ethash
[7] Cryptocurrencies without Proof of Work
[8] PPC:一种P2P(点对点)的权益证明(Proof of Stake)密码学货币
[9] BlackCoin's Proof-of-Stake Protocol v2
[10] Security Analysis of Proof-of-Stake Protocol v3.0
[11] The missing explanation of Proof of Stake Version 3
[12] Proof of Stake FAQ
[13] Qtum's PoS vs CASPER (and the nothing-at-stake problem)
[14] Block size limit controversy
[15] EOS.IO Technical White Paper
[16] NEO共识机制
[17] 微信PaxosStore:深入浅出Paxos算法协议
[18] Raft一致性算法笔记
作者:QTUM量子链开发团队
链接:https://juejin.im/post/5ac1e9adf265da23906c2dc8
来源:掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。

专访 Mable Jiang:复盘 Multicoin 投资方法论与 DeFi 洞察
原文标题:《对话 Mable:复盘 Multicoin Capital 的投资方法论与 DeFi 观察 | 链捕手》受访者:Mable Jiang,Multicoin Capital 执行董事撰文:王...

信标链、PoS、分片……接触以太坊 2.0 得先理解这些术语
原文标题:《以太坊 2.0 术语库》整理:ETH 中文网Attestation 证明证明是指验证者所发起的投票,由验证者的签名聚合而成,用以证明区块的有效性,投票通过验证者的余额进行加权。Attest...

手把手教你搭建 IPFS 私有网络
在联盟链的场景下,IPFS 作为去中心化存储的首选方案,本文将介绍如何使用 go-ipfs 搭建一个私有网络并进行简单使用。...