
SHA-256、MD-5…… 哈希散列函数这些原理你懂了吗?



作者:wagslane
译者:火火酱
出品:区块链大本营
本文对哈希函数进行简要的介绍,旨在帮助读者理解为什么要使用哈希函数,以及其基本工作原理。文中将省略具体证明和实现细节,而将重点放在高级原理上。

为什么要使用哈希函数
哈希函数被广泛应用于互联网的各个方面,主要用于安全存储密码、查找备份记录、快速存储和检索数据等等。例如,Qvault使用哈希散列将主密码扩展为私人加密密钥。
(Qvault: https://qvault.io/ )
用途列表清单详见: https://en.wikipedia.or/wiki/Hash_function#Uses
本文将重点介绍哈希函数的几个重要特性,也可以说是其最重要的特性:
- 哈希函数确定性地加扰数据;
- 无论输入是什么,哈希函数的输出大小始终相同;
- 无法从加扰的数据中检索原始数据(单向函数);

确定性地加扰数据
首先,想象一个魔方。

我们从恢复魔方开始。如果我们随机转动魔方,到最后,魔方将会呈现和开始时完全不同的状态。同样,如果我们重新开始,重复完全相同的动作,那么我们会不断得到完全相同的结果。尽管看起来结果可能是随机产生的,但实质上并非如此。这就是“确定性”的意思。
iLoveBitcoin→ “2f5sfsdfs5s1fsfsdf98ss4f84sfs6d5fs2d1fdf15”
现在,如果有人看到这个加扰后的版本,他们也不会知道我的原始密码!这一点非常重要,因为这意味着,作为一名网站开发人员,我只需存储用户密码的哈希散列(加扰数据),即可对其进行验证。
当用户进行注册时,我对密码进行哈希散列处理,并将其存储在数据库中。当用户登录时,我只需再次对输入的内容进行哈希散列处理,并比较两个哈希值。 由于特定的输入始终会输出相同的哈希值,所以该方法每次都可以成功验证密码。
如果网站以纯文本格式存储密码的话,则会出现巨大的安全漏洞。如果有人入侵该网站,那么他将会能获取所有的电子邮件和密码,并可以尝试在其他网站上使用这些信息进行登录。

无论输入是什么,输出大小始终相同
如果对单个单词进行哈希,则输出将是特定的大小(对于特定的哈希函数SHA-256来说,其大小是256 bits)。如果对一本书进行哈希,其输出也将是相同的大小。
这是其另一个重要特性,因为这可以节省我们的计算时间。典型的例子是在数据映射(data map)中使用哈希散列作为键(key)。数据映射是计算机科学中用来存储数据的简单结构。
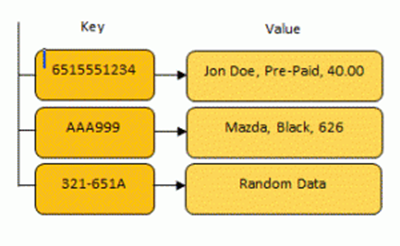
当程序在映射中存储数据时,会向映射提供键(key)和值(value)。当程序想要访问该值时,它可以向映射提供适当的键并接收相应的值。数据映射的优势在于它们可以立即找到数据。该键被用作计算机能够立即找到的地址,这样一来,就不必花费数小时在数百万条记录中进行搜索了。
因为键就像地址一样,不能太大。如果想将书籍存储在数据映射中,则可以对书籍的内容进行哈希散列处理,并使用哈希值作为键。作为一名程序员,我可以轻而易举地使用哈希散列来查找该书的内容,而不必按标题、作者等对数千条记录进行排序。

其工作原理是怎样的呢?
这部分是本文的难点,我会尽量将其简化,省略实际的实现细节,重点介绍计算机在使用哈希散列处理数据时工作原理的基本概念。
下面让我们来看一下我为此专门编写的一个算法—— LANEHASH :
我们从要进行哈希散列的数据开始

我把字母和数字转换成1和0 (计算机中的所有数据都以1和0的形式进行存储,不同的1和0的组合代表了不同的字母)
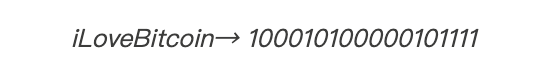
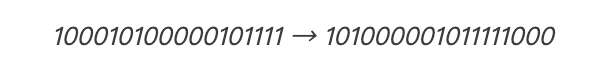
每隔1 位(bit)进行间隔:
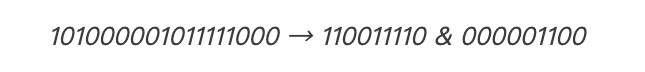
我们把这两部分转换为以十进制的数字。十进制是我们在学校中学过的“正常的”数字系统。(所有的二进制数据实际上都是数字,你可以在其他网站上在线查询如何将二进制转换为十进制数字)
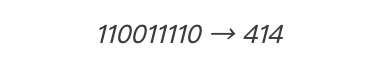
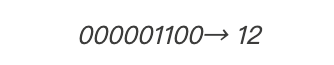
我们将这两个数字相乘:
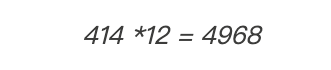
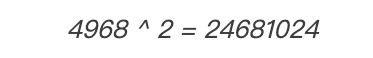
再将该数字转换回二进制:
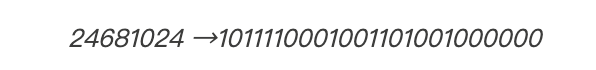
从右侧切掉9 bits后正好得到16 bits:
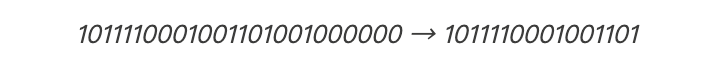
然后将该二进制数据转换回英语:
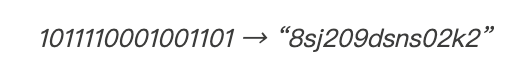
在我将英语转换成二进制,并将二进制转换成英语的步骤中,并没有遵循任何模式。有许多不同的方法可以将二进制数据转换成英语并转换回去,我只是不想在本文中展开讨论这个问题。感兴趣的话,你可以通过以下链接进行了解:
https://en.wikipedia.org/wiki/ASCII


