
科普 | 点对点网络组建:从 Kademlia 到 Discv5



作者: dean
翻译&校对: 裴奇 &阿剑
来源:以太坊爱好者
如果你一直在研究以太坊或者相关的技术,你可能听说过 discv4 或 discv5。但这些究竟是什么呢?它们是如何工作的呢?它们出众的地方在哪里呢?想要回答这些问题,我们需要从头开始梳理一下。这篇博文假定读者对这个领域比较陌生,因此没有技术背景的人也可以阅读。
开篇
故事的开端:在 P2P(peer-to-peer) 网络中,节点的相互发现及网络成型的过程会面临一些问题。
早年间的 P2P 文件共享技术,比如 Napster,使用单个服务器共享信息,信息中记录谁拥有什么文件。某个节点向中心服务器发起连接并提交记录自己所拥有文件的列表。另一个节点之后向同一个中心服务器发起连接,寻找自己所需文件的存储节点,然后和找到的节点建立联系。然而这是一个有缺陷的系统 —— 系统很容易遭受攻击,而且中心化服务器节点可能会吃官司。(译者注:单个服务器上存储文件内容和节点的对应关系,如果提供了一些受版权保护内容的链接关系,那么这个中心化服务器的提供者将直接受到原版权方的法律追责)
因此,点对点网络亟需另一种解决方案。研究者们经过数年研究和实验,提出了分布式哈希表(DHT)。
分布式哈希表
2001 年,研究者们为 DHT 提出了 4 种新的协议,分别是 Tapestry、Chord、CAN 以及 Pastr,这 4 个协议在核心功能上各有取舍和改变,因此拥有不同的特性。
上文中一直都在说 DHT。那么 DHT 到底是什么呢?
分布式哈希表(DHT)是一个分布式的键值列表。参与到 DHT 的节点可以很轻松地检索到某个键对应的值。
假定一个网络中,有 9 个键值对和 3 个节点,理想情况下,每个节点只需要存储 3 个键值对(最好的方式是存储6个键值对,以提供冗余),意味着如果要更新某个键值对,只有部分网络节点需要更新。大致想法是这样的,网络中的任何节点都可以基于信息在节点间分布的方式,知道要去哪里寻找它所需要的特定键值对。
Kademlia
现在我们知道 DHT 是什么了,那我们来看看 discv4 的前身 Kademlia。Kademlia 是 Petar Maymounkov 和 David Mazières 于 2002 年发明的 DHT 协议。我觉得这个协议可能是最流行,而且使用最广泛的 DHT 协议。它的工作原理很简单,让我们来看看吧。
在 Kademlia 中,节点和值通过距离来排列(其排列有严格数学化的定义)。这里的距离不是地理位置上的距离,而是基于标识符的表示方法。通过使用一些距离函数,可以计算出两个标识符之间的距离。
Kademlia 使用 XOR(异或操作符) 作为距离函数。XOR 函数的特点在于,只有当输入不同时,输出才为 true。下面是用二进制标识符表示的例子。
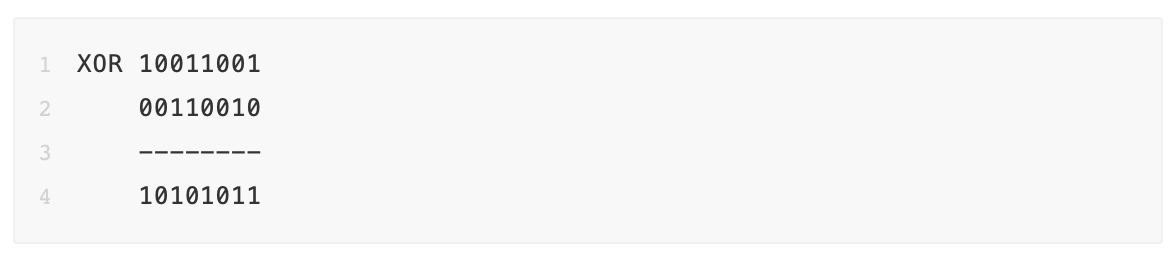
上面的这个例子是说,十进制数字 153 和 50 之间的距离是 171。
使用 XOR 作为距离函数有很多原因,包括:
- 某个 ID 与它自己的距离是 0。
- 距离是对称的,A 到 B 的距离和 B 到 A 的距离相同。
- 遵循三角不等式,如果 A,B,C 是三角形上的三点,那么 A 到 B 的距离,小于或等于 A 到 C 的距离加上 B 到 C 的距离。
Kademlia 节点存储着一个路由表。路由表中包含多个列表。每后一个列表所记载的节点都比前一个列表中的节点离得远一点。每个节点维护离自己最近节点的信息;另一个节点离得越远,本地节点保存的相关信息就越少。
假定我想要找到一个特定的节点。我要做的就是向我已知的节点发送请求,这些节点返回他们的记录中离我的目标节点更近的邻居节点。我重复此过程,直到某群邻居帮我找到目标节点。
对值来说也是同样的过程。值跟节点之间的距离是确定的,因为值和节点的标识符 ID 以相同的方式组织,因此我们可以计算这个距离。如果我想查找一个值,我只需要寻找离这个值的键最近的邻居节点,直到找到存储这个值的节点。
为了让 Kademlia 节点支持这些功能,协议通过下面这些消息来通信。
- PING - 用来检测一个节点是否还在运行。
- STORE - 在一个节点上存储给定键的值。
- FINDNODE - 向给定 ID 返回所请求的最近节点。
- FINDVALUE - 和 FINDNODE 一样,区别在于,如果一个节点存储着特定的值,它将会直接将值返回。
Discv4
对背景做好铺垫之后,终于来到 discv4(表示 discovery v4) 了,这是以太坊当前的节点发现协议。Discv4 协议本身是基于 Kademlia 的,但在某些部分做了改动。例如,discv4 中不再使用 DHT 中的值部分。
Kademlia 主要用于网络的组织,因此我们可以使用路由表定位其他节点。但 discv4 中完全不使用 DHT 中的值部分,因此我们可以抛弃 Kademlia 中使用的命令 FINDVALUE 和 STORE。
前文中,Kademlia 的查询方法描述了节点如何得到对等节点。节点向另一些节点发起请求,得到离自己更近的节点。重复此请求过程,直到无法找到任何新的节点。
此外,discv4 添加了相互的终端验证功能。这是为了确保发起 FINDNODE 请求的节点正在参与同一个节点发现协议。
最后,所有的 discv4 节点都应该维护最新的 ENR 记录。记录里包含一个节点的信息。任何节点都可以使用特定于 discv4 的包,叫做 ENRRequest,去请求 ENR 记录。
如果你想知道关于 ENRs 的更多细节,请移步至我的另一篇博文 Network Addresses in Ethereum。
然而,discv4 也引入了一些问题。让我们来看看其中的几个。
首先,按照 discv4 目前的工作方式,是无法区分节点间的次级协议的。也就是说,如果一个以太坊节点将以太坊 Classic 节点,Swarm 或 Whisper 节点加入它的 DHT,那么只有和这些节点发生多次通信之后,才能发现这些节点的无效性。这种无法区分次级协议的能力使得它很难找到特定的节点,比如支持轻客户端的以太坊节点。
其次,为了防御重放攻击,discv4 使用了时间戳。当某个主机的时钟发生错误时,这种方式会导致各种各样的问题。欲了解更多详情,请查阅 discv4 规范的 “Known Issues” 部分。
最后,终端的互验证工作中也存在问题。因为信息有丢包的可能,所以没有办法断定两个对等节点是否都已验证过对方。也就是说,我们可能自认为已经被验证过了,但跟我们通信的对等节点却并不这么认为;他们可能会因此丢弃我们的 FINDNODE 包。
Discv5
最后,让我们来看一下 discv5。Discv5 是 discv4 的迭代版本,将作为 Eth 2.0 的节点发现协议。Discv5 旨在修复 discv4 中存在的诸多问题。
第一个改变是 FINDNODE 的工作方式。传统的 Kademlia 以及 discv5 都使用标识符。而在 discv5 中,我们使用对数距离,也就是说,发送 FINDNODE 请求后,响应中包含的节点,都与发送方节点在特定的对数距离内。
对数距离指:先计算出距离,然后使用以 2 为底数的 log 函数,即 log2(A xor B)。
其次一个很重要的改变就是 discv5 一直致力于解决的,存在于 discv4 的最大问题:次级协议的区分。Discv5 添加了主题表(topic tables)。主题表是先进先出的列表,表中包含提供特定服务的节点。节点通过在对等节点中注册广告将自己添加进这个列表。
截至本文写作之时,这个次级协议区分方案中的写操作依然存在一些问题。对一个节点来说,目前没有有效的方法将广告发布在多个对等节点上,因此需要向每个对等节点发送单独的请求,这对于大规模网络来说效率很低。
此外,一个节点向多少个对等节点上发布广告,以及向哪些对等节点投放都是不清楚的。更多详情请查阅 devp2p#136 。
Discv5 中还有很多小的改变,但是这些改变没那么重要,因此在这篇总结中就省略了。
虽然 discv5 解决了一些 discv4 中存在的问题,但还有一些问题,discv5 仍没有解决,比如不可靠的终端验证。写这篇博文之时,discv5 还没有提出新的方法去提升终端验证的处理过程。
正如你所见,discv5 的工作仍在进行中,目前还需要克服一些很大的挑战。如果这个协议解决了这些问题,那么它将会是对原始 Kademlia 实现的一个巨大提升。
希望这篇文章能帮助你理解什么是发现协议以及发现协议是如何工作的。如果你对整个协议感兴趣,可以在 github 上查阅。
原文链接: https://vac.dev/kademlia-to-discv5


