
AIGC:自动化内容生成,AI的下一个引爆点?



随着5G大带宽网络时代的到来,人们对更具有视觉表现力的数字内容越来越渴望。传统数字内容的生成效率已成为新时代的瓶颈。 作为下一个探索热点,「AI自动化内容生成」激发了大量行业需求,也让我们看到了人工智能技术新的引爆点 。
自动化内容生成并不是第一天诞生。但过去的2D/3D非结构化内容生成效果不尽人意,而且遗留了很多历史问题给创业者去解决。 近年来,AI在CG领域的应用,尤其是若干革命性模型的提出,给整个方向带来全新思路,其影响还在持续发酵中 。 但技术终将服务于商业。我们也看到,AI内容生成技术正在各类显性的商业场景中落地,创造越来越多的现实价值 。
本文将阐述AI与内容生成的发展现状,探究目前技术的难点和机会,同时也会带大家从不同角度看未来的商业价值。
自动化内容生成并不是第一天出现
2022百度世界大会上,百度首席技术官王海峰展示了利用AI「补全」《富春山居图》让历史画作重现当代。风格与现存真迹的一致程度也让专家大为震撼。

▲ 浙江博物馆馆藏《富春山居图·剩山图》局部(左),台北故宫博物院馆藏《富春山居图·无用师卷》局部(右)
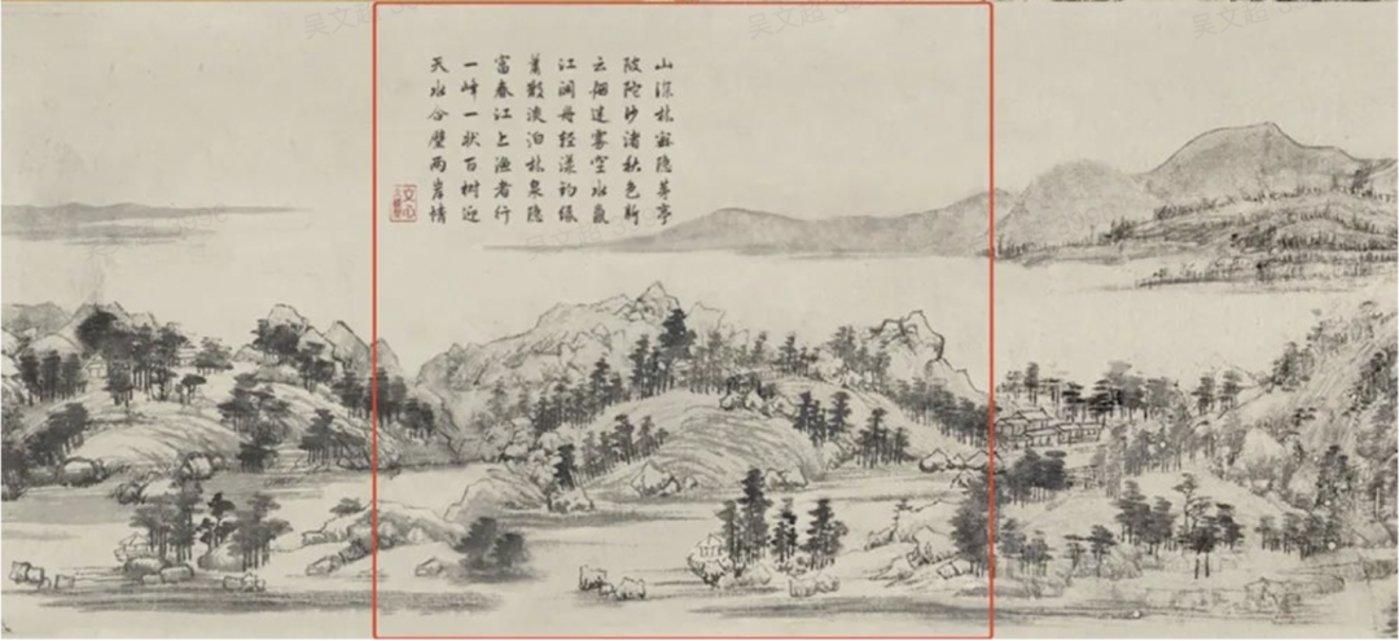
▲ AI补全《富春山居图》并题诗(上图红框处)
李彦宏在大会上分享了 AIGC(AI Generated Content) 将走过的三个发展阶段:
第一阶段是「助手阶段」 ,AIGC辅助人类进行内容生产; 第二阶段是「协作阶段」 ,AIGC以虚实并存的虚拟人形态出现,形成人机共生的局面; 第三阶段是「原创阶段」 ,AIGC将独立完成内容创作。
AIGC这个词听上去比较时髦,但自动化内容生成并不是个很新的概念。利用计算机辅助人类进行内容生产其实很早就出现,比如在计算机编程领域IDE的代码提示、使用Office Word编辑内容的错误修正,到后来利用NLG自动化文本生成等都可以算作这个范围。
近年来,承载内容的媒介越来越丰富,从最早的文本到图文、视频到3D内容。同时也带来了对内容快速生产的更大诉求,激发了大家持续探索自动内容生成的动力。 深度学习的出现和发展,进一步带来了从CV(Computer Vision)延展到CG(Computer Graphics)领域的各种新尝试 。让传统的通过规则、数据的富媒体内容生成方法逐步延伸到基于深度学习的内容生成。这也是目前大家狭义理解的AIGC概念。
2D/3D非结构化内容生成更具有挑战性
数字内容的载体越来越丰富,针对各种形态的AI内容生成的研究也越来越多,包括文字的NLG(自然语言生成)、图片/视频的自动风格迁移和生成、通过点云/图片信息自动生成3D内容等。 本文更加关注和深度学习算法更加契合也更有视觉表现力的「2D和3D非结构化内容生成」 。
2D内容生成
毋庸置疑,2D最常见的表现形式是图像,视频本质上是多帧的连续图像。
传统的2D图像生成的主流方式是通过摄像头拍摄的方式物理采集实景图片,或者通过Photoshop等设计/绘图工具绘制数字图片。实景拍摄图片受限于环境、光照和拍摄技术等因素,导致优质图片的生成难度较高。而数字图片更多是体现作者的绘画和美术功底。
如何通过既有素材快速且批量生产可用优质图片,也是近年来2D内容生成的重要研究方向,而这里面大放异彩的深度学习算法莫过于GAN(对抗神经网络) 。
3D内容生成
3D内容生成更加复杂。要理解3D内容生成,首先可能还是得明确下什么是3D内容。
D是dimension的缩写,顾名思义,3D是指物体本身的3个纬度(X-Y-Z)。在物理世界比较好理解,大家能看到的空间中所有物体都是三维的,因为我们的空间就存在XYZ三个纬度。
但在2D平面的计算机世界3D又该如何理解?
其实很简单,以我们常见的3D建模软件为例,我们建立的模型虽然是在2D屏幕上呈现, 但你可以按照计算机设定的XYZ三个坐标轴进行移动(Move、Rotate、Scale)来从各个角度看到物体的各个面 。所以多角度的概念才是我们通常理解的3D数字内容。
如果要在体验上有真正的3D感,需要突破2D屏幕的限制,那就只能等待AR/VR、全息显示等新交互设备的发展了。
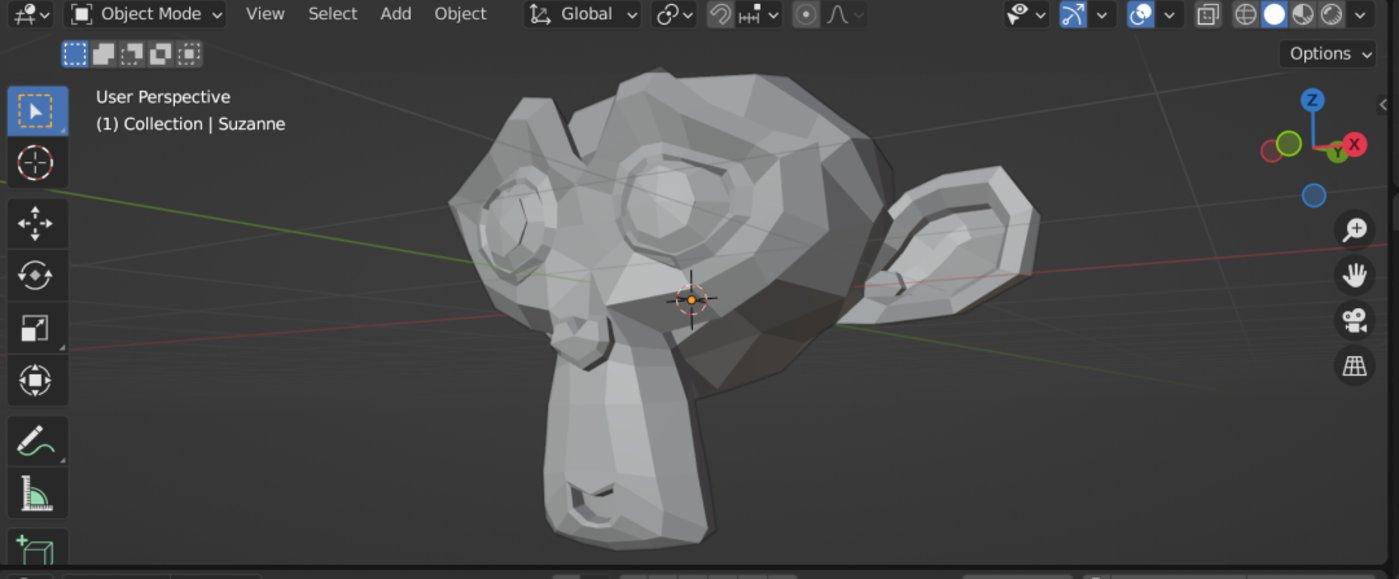
▲ Blender中的三维模型可以按XYZ三个坐标轴多维变化
除了几何形状,完整的3D内容还包含材质(贴皮),再结合光照,最终通过渲染形成多角度的RGB图片。
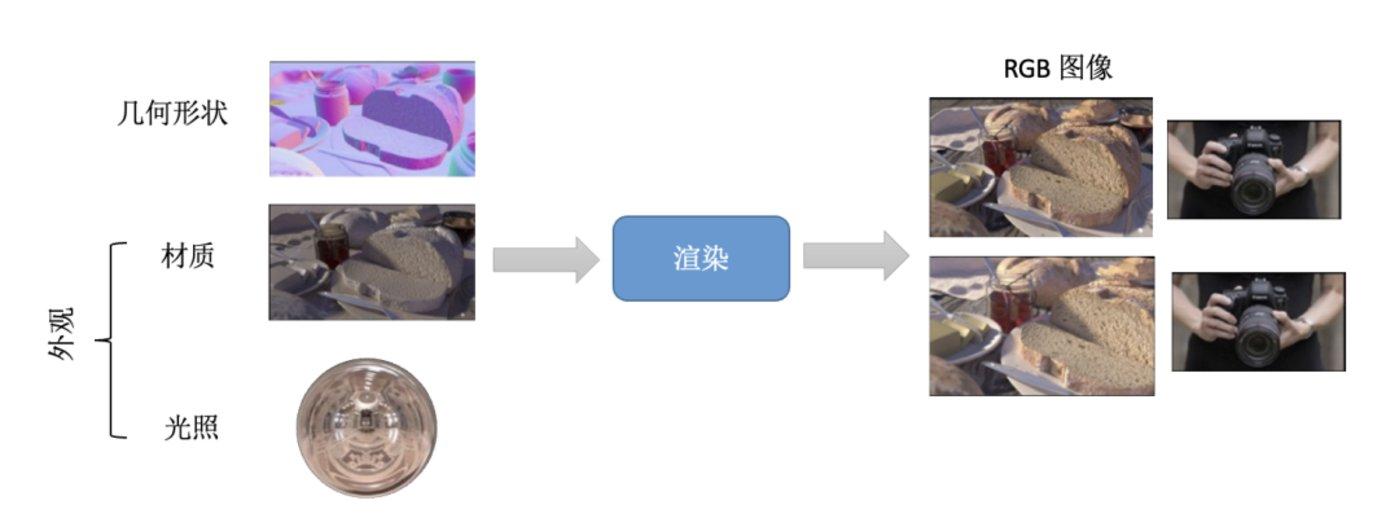
▲ 3D内容是将形状和外观进行组合渲染形成多维度视角的2D图片
3D内容生成的本质是如何构建物体的几何、材质和光照。元素的多样性和复杂性,让3D内容生成成为CG领域的一个难点 。
以第一步的几何形状的表达来看,业内目前没有统一的表达方式 。常见的几何表达包括显式和隐式两类。显式更多的是指以肉眼可见的方式来表达几何图形。常见的显式表达方式包括在机器视觉应用较多的点云(Point Cloud)、在游戏场景应用较多的体素(Voxel,类似Roblox)和3D建模软件中常用的网格(Mesh)。隐式表达则是用参数化方程的方式来描述一个3D几何,比较知名的如有向距离场(SDF),通过每个像素(体素)记录自己与距离自己最近物体之间的距离来表达,如果在物体内,则距离为负,正好在物体边界上则为0。
不同的3D表达方式没有统一的规范,导致3D内容的生成和制作与2D相比难度更上一层楼 。
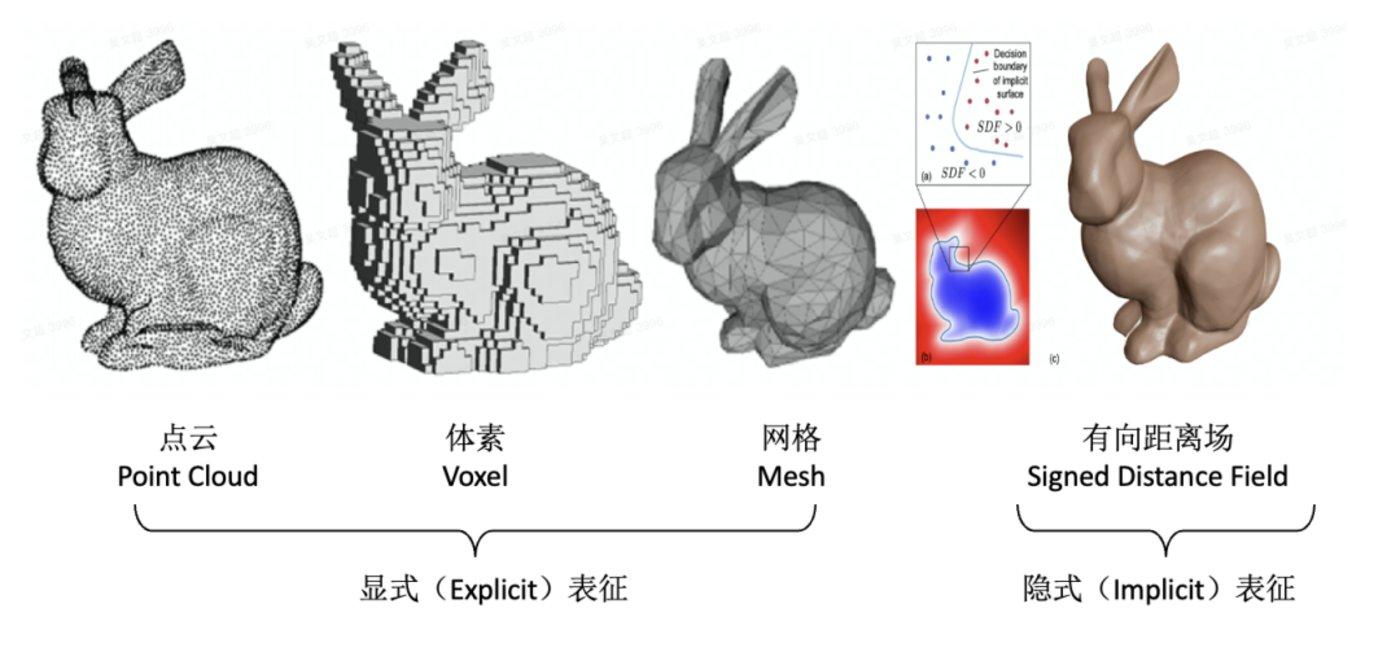
▲ 多样的3D几何表征方式
传统3D内容生成需要设计师使用Maya、3DMax、工程建模CAD等3D建模软件手动建模/渲染出来,但软件学习成本高、建模本身效率低等原因导致该方案难以快速批量生成3D内容。
一种创新方法是通过既有2D数据自动重建3D模型 。传统三维重建方式为通过激光扫描生成目标物体的点云数据后进行三维重建,但这种方式采集的点云数据是离散并且无严格拓扑关系的,导致无法生成高分辨率的模型。
目前AIGC研究的重点方向,是通过若干2D图片以计算机视觉算法重建方式来生成更多的3D内容 。基于图片的3D内容生成可以理解为下面的流程,通过现有2D图片(输入)进行3D几何、材质等重建,再结合光照渲染能力重新恢复2D高清的多维度图片。
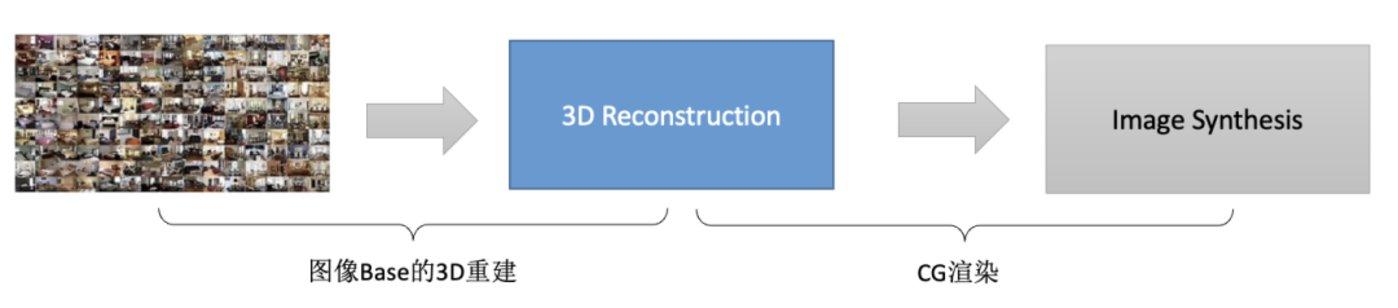
虽然2D图片采集相对容易,但问题在于,很难把物体任意维度的数据都拍得很完整,而且有些物体反光、透明等原因导致拍摄的图片质量不高。如何在有限的数据量和有限质量的数据下根据先验知识构建成一个完整的多维数据,正是深度学习擅长的问题。
除了静态的人/物体/场景本身,如何构建更加复杂的动态内容也是内容生成的重要部分。以人举例,3D内容包含人的动作、物理碰撞模拟(物理引擎)等也都是AI内容生成需要进一步解决的问题。
当然问题越多,给予创业企业突破创新的机会也才越多。
AI给CG领域带来全新的技术变革
近年来,AI给二维和三维的内容生成带来了许多新变化。
GAN神经网络
在二维领域,最重大突破便是Goodfellow在2014年提出的GAN神经网络。GAN包含有两个模型,一个是生成模型(generative model),一个是判别模型(discriminative model)。可以通俗理解为: 生成模型像「一个造假团伙,试图生产和使用假币」,而判别模型像「检测假币的警察」 。
生成器(generator)试图欺骗判别器(discriminator),判别器则努力不被生成器欺骗。模型经过交替优化训练,两种模型都能得到提升,但最终我们要得到的是效果提升到很高很好的生成模型(造假团伙),这个生成模型(造假团伙)所生成的产品能达到真假难分的地步 。
利用GAN网络衍生的如CycleGAN、StyleGAN等神经网络模型,就可以通过既有图片进行图片的风格迁移、人脸编辑、图像修复、补全等操作而形成新的内容。前文中提到《富春山居图》的补全也一定程度上是这类算法的延伸。
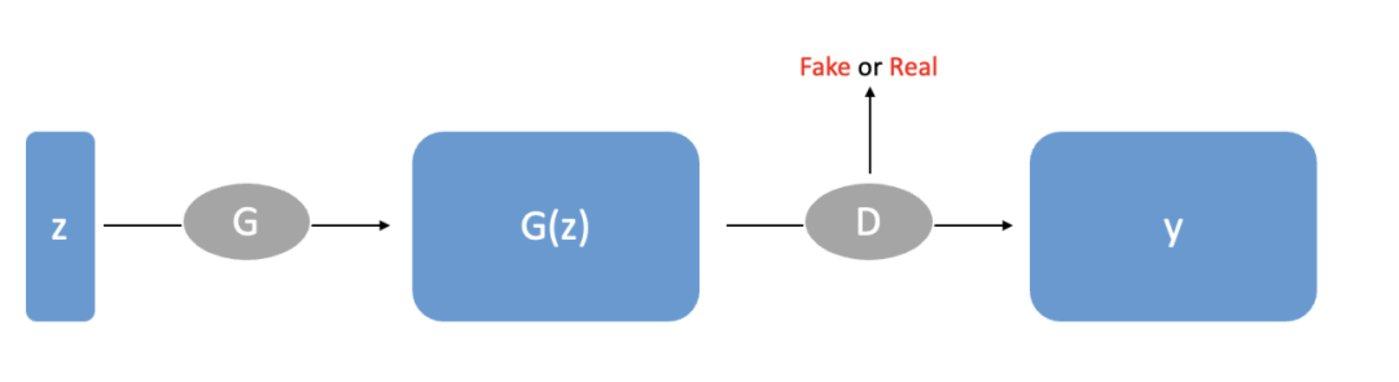
▲ GAN网络生成器和判别器「对抗训练」
在三维领域,因为表达形式的复杂性,业界围绕不同表达形式也在各个方向进行探索。
点云重建
由于采集成本高、遮挡等问题,点云无法连续采集物体表面的信息,而更加容易表征空间定位信息。 点云3D重建在自动驾驶、机器人等空间定位和扫描场景应用更多,并不太适合用于视觉表现 。要生成更加稠密包括适合视觉观测的3D内容的表面,需要生成更加稠密的点来补充离散点云的稀疏问题。这其中也有些研究者利用深度学习的方法,通过特征扩展、GAN扩展网络等方式生成更加稠密的点云信息。

▲ 深度学习+点云进行3D表面重建
传统图片3D重建
从2D图片重建3D模型并非在近年来AI大发展之后才出现,比较早的算法如Structure From Motion(SFM,1979年前)、Multi-View Stereo(MVS,2006年以前)、PMVS(2010)和COLMAP(2016)等。
以效果还不错的PMVS算法举例,从图片里面提取特征再做三角测量的点,获得点云数据,然后根据这些点重建物体表面,并进行纹理映射,就可以还原出三维场景和物体了。
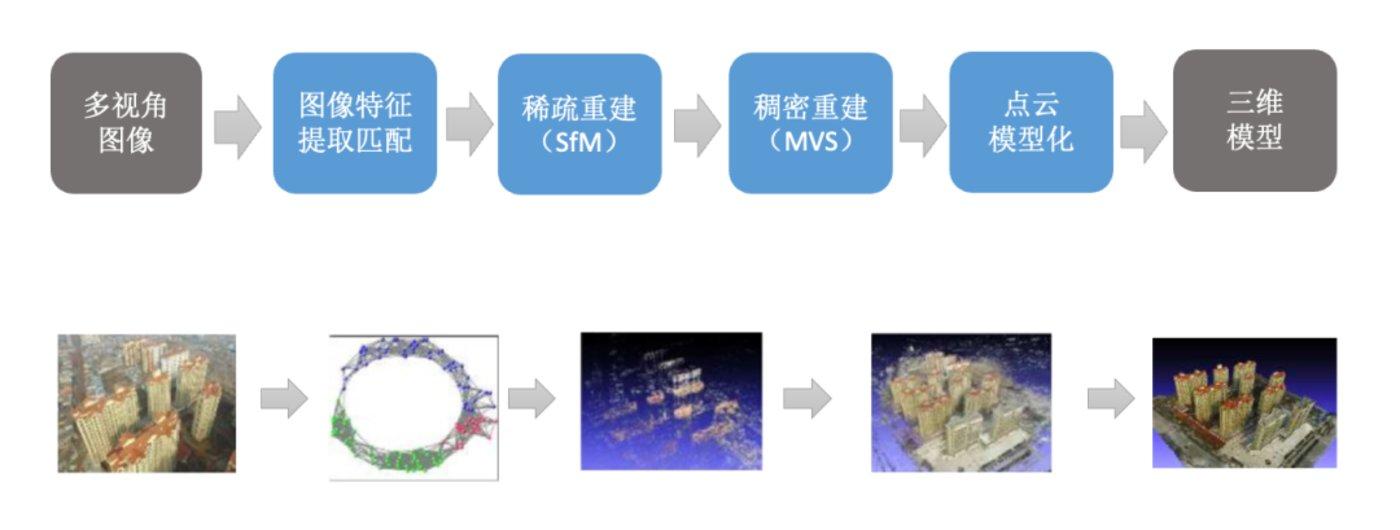
▲ 结合SFM和MVS的PMVS算法
但这种方法同样因为噪声、点云稀疏问题无法形成完整的几何结构,需要更多的人工加工,才能真正为图形学使用。而一个完美的图像渲染过程需要一个完美的多几何结构和材质,所以这种方式很难达到渲染需要的质量。

▲ 点云稀疏问题导致无法形成完美质量的3D几何结构
基于AI算法的图片3D重建
深度学习等AI算法的提出,最先解决了计算机视觉领域中物体识别、内容理解等问题 。随着近年来不同深度学习模型的提出,大家逐步关注到如何把深度神经网络应用在CG领域。
要进行3D重建,首先要解决的便是几何的表征方式选择问题,即选择显式还是隐式表达 。
显式表达近年来涌现出不少优秀的研究成果:GQN(2018)、CodeSLAM(2018)、DeepVoxels(2019)、Neural Volumes(2019)、Latent Fusion(2020)。但显式表达最大的问题在于几何表征本身是离散的,几何拓扑关系难以优化。导致生成的三维内容的分辨率受到比较大的限制。
为了获得更加准确、高分辨率的3D内容,隐式表达方式开始成为大家主要研究的方向 。隐式表达中,最容易想到的便是对现有隐式表达利用深度学习改造,如DeepSDF模型,但受限于表达方式的缺陷,效果也不尽如人意。2020年, 谷歌研究院的Pratul Srinivasan、Benjamin Mildenhall等提出的NeRF方法引爆了整个3D重建领域 。NeRF的提出激发了大量的后续研究,原始研究文献实现了增长极快的引用率,迄今NeRF的引用量已破千。
我们来一探这个可能开启CG领域新时代的深度学习算法:NeRF是Neural Radiance Fields的缩写,其中的Radiance Fields是指一个函数,也就是前面提到的隐式表达中的表达函数,当然除了表征几何,Radiance函数同样带上颜色信息来完成对材质-贴图的表征。
NeRF将场景表示为空间中任何点的volume density σ(简单理解为不透明度) 和颜色值c 。有了以NeRF形式存在的场景表示后,就可以对该场景进行渲染,生成新视角的模拟图片。NeRF的输入为空间点的位置和方向,通过求解穿过场景的任何光线的颜色,从而渲染合成新的图像。
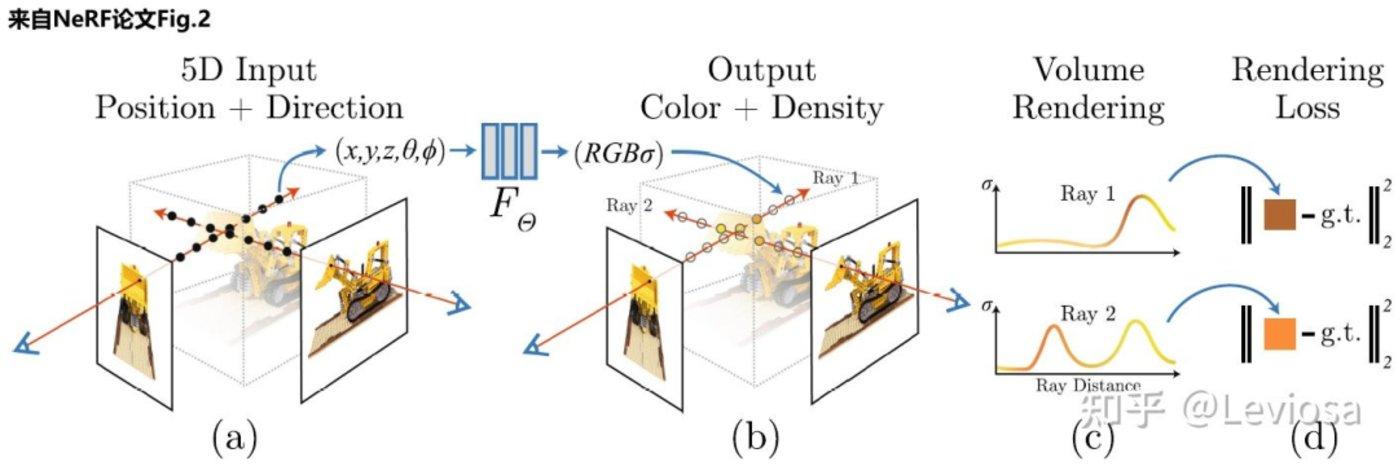
▲ NeRF的简单描述(输入是空间位置信息,输出是透明度+颜色)
可以看出NeRF最大的创新在于对场景的隐式表征方式的创新,通过连续的隐式表征,可以用少量的图片渲染重建出更加逼真的三维内容 。

▲ NeRF网络和现有深度神经网络效果对比
NeRF也不是没有缺点——由于需计算大量的点位信息导致推理过程过于耗时而很难实现实时渲染;缺乏显示表征而带来内容编辑难度较高 。因此,围绕后NeRF时代的神经网络模型和方法也层出不穷。通过将GAN和NeRF两大内容生成的AI技术相结合的GRAF9(Generative Radiance Fields)。2021年CVPR的最佳论文GIRAFFE通过GAN网络实现NeRF的可控编辑等。
AI+Motion
现实世界是在叙事基础上建立,而叙事由人物关系展开,所以人是现实世界最重要的元素 。
除了外形表现,人更重要的是灵活的动作/表情的表达和交互,只有配合动作/表情,人物的「神」和「态」才能完整地被表达出来。 可以说,没有动作的人物模型毫无意义 。
模型建立虽然有不同层次的成本,但始终可以通过手工或者半自动的方式完成,制作门槛并不高。但如何生成符合人体运动学的动作和表情则更加需要数据的支撑,也非常适合利用AI算法来进行模型的训练。
动作生成的难度在于如何用相对标准化的方式来驱动不同外形的人物,同时模型本身足够的协调和自然。这不仅是指动作本身的协调程度,更重要的是还要和语音、文本等多模态输入能够完美结合 。
近年来,随着动捕技术发展、视频内容数据的丰富,动作数据的积累也变得更加简单。大量围绕动作驱动的AI工作也陆续被大家提出。2019年以后大量的工作基于RNN网络进行动作预测(Motion Prediction)、基于 RL(Reinforcement Learning,增强学习)的动作控制算法(Motion Control)和Ginosar、Alexanderson等人提出的基于语音、文本甚至音乐的多模态动作驱动的CNN模型(Cross-modal motion synthesis)。

▲ 通过语音驱动手势动作示例
AI+CG的价值落地明确并且正在发生
我们并没有必要过多讨论具体的算法,更应该关注的是, 在当前技术成熟度下AI+CG能创造多大的商业价值 。
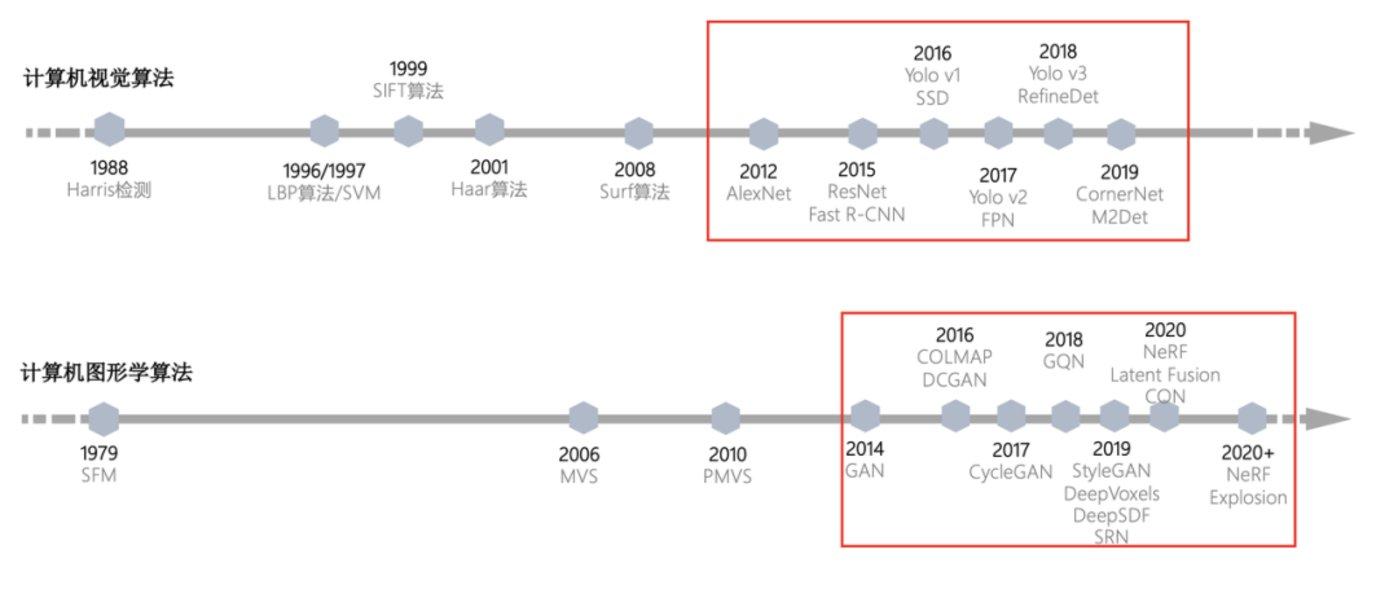
首先我们来看看CV领域的趋势,在2012年AlexNet被提出以前,计算机视觉中的检测、目标识别其实已经有超40年的发展历史,但由于技术成熟度的原因迟迟没有很好的商业落地。随着深度学习等AI技术被验证,大量的相关工作在随后的6-7年内被提出,随之而来的是AI被应用在各个商业场景。
这其中首先有杀手级的应用——人脸识别,在支付、安防、身份认证等领域都得到了广泛的应用。除了人脸相关,我们再扩展到物体的视觉检测方向,有工业视觉检测、机器视觉等行业应用。这些应用带来了大量的生产力提升,同时也创造了极大的社会价值和投资机会。
那AI+CG领域是否存在同样的机会呢?
从技术发展的角度看,CG似乎和CV领域一样,正迎来AI在CG领域的大爆发的前期。整个发展路径非常类似,其中比较有代表性的两类模型是GAN和NeRF以及大量的延伸工作,但提出的时间比AlexNet和ResNet等晚了3-5年,技术仍处于爬坡期。然而我们更需要关注的是,目前具有一定AI技术成熟度的CG领域,未来到底有多少商业价值呢?
无论是2D还是3D,更多是为了视觉而服务,我们能想到或者日常能够体验到的视觉场景大致包括以下几类: 视觉内容营销、线上的商业服务、行业仿真和新的交互方式带来的泛娱乐内容的需求 。
视觉内容营销
互联网时代开启后,营销是流量企业最主要变现方式之一。 而承载营销最重要的方式便是更加具有视觉冲击力的图文、视频等富媒体内容 。
首先从视频类(图文类似)内容生成成本角度来看,传统的营销类视频以拍摄+后期制作的方式为主。视频的生产过程都耗费大量的人力,并且视频多样化往往需要简单重复劳动来获得。
举个最简单例子,同一个产品营销类视频,产品在不同的国家进行售卖,可能需要当地风格的模特进行视频表现,但如果使用GAN系列模型通过AI生成和风格迁移的方式,可以较为完美地进行人物风格切换,快速降低内容制作成本。

▲ 由GAN网络生成的不同图片风格
其次从效果来看,传统线上视频类营销往往以产品介绍、特点宣传为主。和线下营销关注「人货场」的概念差别比较大,这其中最大的差别在于如何在二维的屏幕模拟出3D的沉浸感,给人以3D式的营销体验。而要有3D沉浸感首先得有3D可交互的内容。
从「人」的角度来看,就涉及到现在比较火的3D数字人的生成 。3D人可以赋予视频内容中人物更加多角度、更多动作、更加可控的展现形态,叠加上深度图效果和语言,让人物更加具有表现力。当然如果能做成「老黄」那样超写实的虚拟人就更加能够以假乱真了。
而这其中就可以利用前面提到的AI的方式进行3D模型和动作的生成,当然仅仅通过AI实现超写实的3D人物构建,在效果上目前还是有些难度,而表情和动作的生成已经做的非常逼真。晨山投资的中科深智便在人物表情和动作生成方面具有多年的积累,并且较早就在行业得到广泛应用。
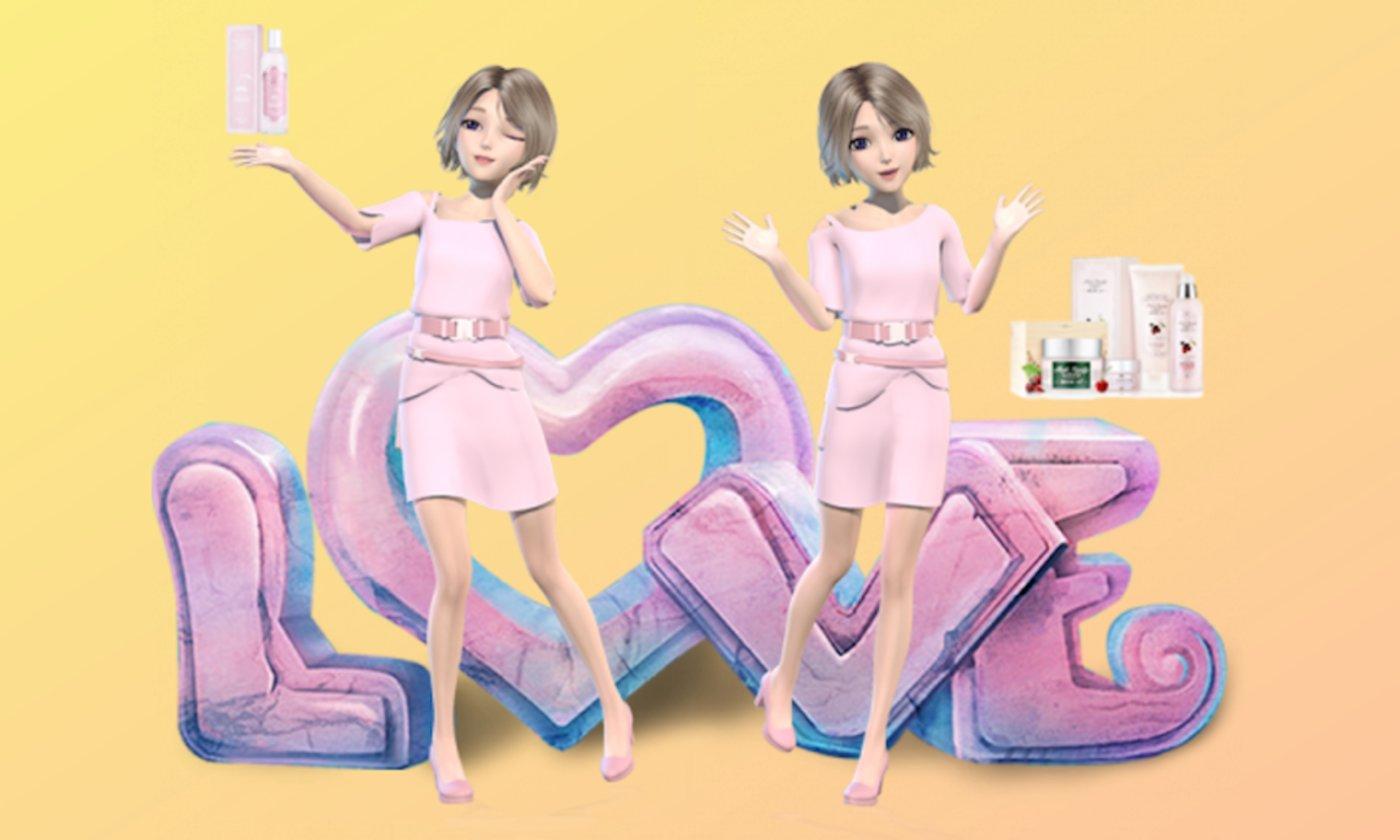
▲ 3D数字人给营销以更加强的表现力
从「货」的角度来看,大家或许已经发现,某些电商平台的内容展示更加立体,会从各个角度来呈现客户想要购买的商品 。品牌方通过拍摄多角度照片,利用AI+3D重建来进行3D商品展示的方式已经越来越普遍,细节表现力也更强。随着NeRF等算法的改进,重建成本逐步降低,未来商品的3D化也将是趋势。

▲ 某电商品牌的3D内容展示
在「场」的层面,如何重现线下体验,追求品牌的「永久在线」,是现在很多平台在探索的方向 。通过线上空间3D化,可以让参与者更加有沉浸感。这就涉及到如何进行空间的建模,通过AI+点云/机器视觉重建的工作已经在一些领域被大家提出和应用。
线上商业服务
近年来,从传统的工业到线下服务业,大家开始使用硬件机器人来替换重复劳动的工作以达到降本增效的目的。
但我们往前一步看, 线上重复的服务工作如客服、电商/电视的主播、播报员甚至部分节目主持人,未来同样有被虚拟机器人替换的可能 。举个例子,大家看天气预报,会因为主持人换了而不看天气预报的可能性有多大?而且他们原生就在线上输出服务,拥有的数字基础其实更好。
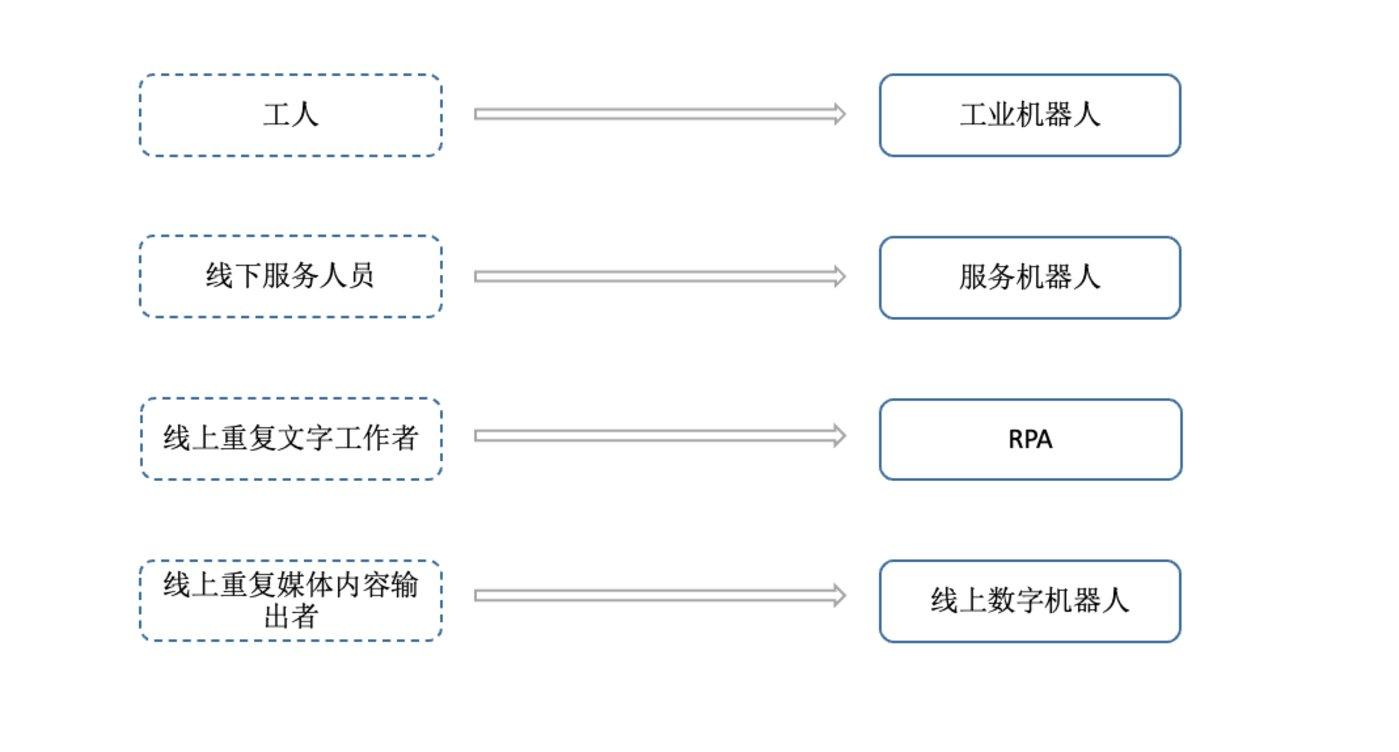
▲ 机器替人的场景在不可逆地发生
很明显,数字员工在降低劳动成本,全天候工作提升工作效率,填补人才缺口,降低人员流动风险等方面有天然的优势。 但前提是如何通过AI的方式结合3D人物生成、更加灵活的动作驱动、更加平滑的解决用户问题,实现更加拟人化甚至无差别化服务 。这些都是是需要根据具体场景,结合进一步的技术驱动来完成的,其中的工作量不容小觑。
或许很多人都会说拟人毕竟还是假人,尤其是虚拟人不够形象,但时代在变,大家的习惯也在变化。对大部分95后、00后来说,二次元或许更受他们青睐。据统计,B站用户平均年龄为21岁,这些人成年后依然保持着对虚拟人物和二次元文化的热爱。
行业仿真
根据最终用途,仿真类应用大致分为管理类仿真和设计类仿真。 对应到我们经常听到的概念便是数字孪生和工业设计软件。二者除了应用方向的区别外,在技术上,前者更加关注效果和数据的结合,而后者关注的更多是物理/几何世界的数字化模拟 。


▲ 数字孪生vs.工业设计
无论数字孪生还是工业设计,历史上的生产方式还是依靠大量的人力在进行内容的建模。这其中不仅仅有重复劳动,而且无论宏观如数字孪生还是微观如工业结构件,其中的模型数量都非常大。如何通过AI快速生产内容、更好地渲染,都是大家目前在努力的方向。
AR/VR
这个方向一直反复成为投资人追捧的热点。 因为大家知道,前面所有的场景,只有能把屏幕变成3D的,那3D才能完全发挥它的能量 。这个趋势虽然跌跌撞撞,但它却在悄然发生。
2020年发布的Oculus Quest 2已达到消费级水平,在显示参数、外观设计和价格等方面均满足了VR用户的基本需求。据IDC数据显示,2021年全球VR出货量达1,095万台,已突破年出货量一千万台的行业重要拐点。
除了设备本身,内容生态同样重要。Oculus为代表的内容数量也在快速提升,截止2022年4月,Oculus Rift、Quest、APP Lab平台分别拥有1,381、357、1,074款应用。这其中的内容包括VR游戏、沉浸式社交等各种3D内容构建的场景。
未来VR加速发展离不开内容的快速生成,当设备不再是瓶颈后,如何抢占内容开发者,高效地给开发者提供更加智能化、AI化的生产力工具才是平台厂商下一步需要布局的重点。这其中Meta已经做出了表率:2021年10月,Meta宣布设立1,000万美元的「创作者基金」,鼓励更多内容创作者进行VR内容创作。至于AR,大家似乎都在等另一个巨头的声音。
AI算法的使用可深可浅,所以一个领域的爆发必然带来鱼龙混杂的企业竞争。AI的行业应用也不可能一步到位,不成熟是行业早期的必然现象,真正需要创业团队做的是耐心且长期地深入产业打磨产品。AIGC方向从业企业对技术、场景和数据的理解和积累显得尤为重要,晨山将持续关注拥有自身技术和经验积淀的匠人,同时又对商业价值充满信心的优秀团队。

Bitcoin Price Consolidates Below Resistance, Are Dips Still Supported?
Bitcoin Price Consolidates Below Resistance, Are Dips Still Supported?
XRP, Solana, Cardano, Shiba Inu Making Up for Lost Time as Big Whale Transaction Spikes Pop Up
XRP, Solana, Cardano, Shiba Inu Making Up for Lost Time as Big Whale Transaction Spikes Pop Up
Justin Sun suspected to have purchased $160m in Ethereum
Justin Sun suspected to have purchased $160m in Ethereum